
如何将具有不同(&重复)分隔符的字符串分隔为多列?
如何将具有不同(&重复)分隔符的字符串分隔为多列?
提问于 2022-04-02 14:46:42
我很难将一列中的数据分成多个列--数据有多个分隔符。我检查了堆栈溢出解决方案,但找不到符合我情况的解决方案。
输入
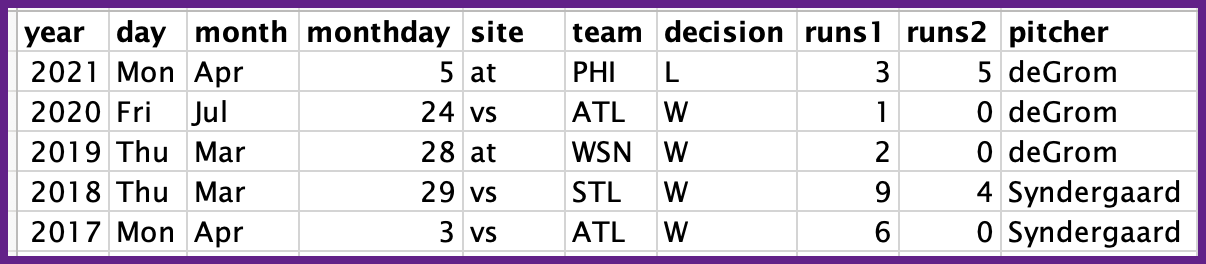
我的尝试
df %>%
separate(col = game, into = c("year", "day", "month", "monthday", "site", "team", "decision", "runs1", "runs2", "pitcher"), sep = "[. ,-]", remove = TRUE)想要的输出(见输入图像)
Dput
structure(list(game = c("2021. Mon, Apr 5 at PHI L (3-5)#", "2020. Fri, Jul 24 vs ATL W (1-0)",
"2019. Thu, Mar 28 at WSN W (2-0)", "2018. Thu, Mar 29 vs STL W (9-4)",
"2017. Mon, Apr 3 vs ATL W (6-0)"), pitcher = c("deGrom", "deGrom",
"deGrom", "Syndergaard", "Syndergaard")), class = c("tbl_df",
"tbl", "data.frame"), row.names = c(NA, -5L))我更喜欢dplyr结果,但对其他人开放。
回答 5
Stack Overflow用户
回答已采纳
发布于 2022-04-02 15:41:10
许多很好的答案,下面还有一个变化
#replace all punctuation with a space then seperate
df %>%
mutate(game=str_replace_all(game,"[:punct:]"," ")) %>%
separate(col = game,into = c("year", "day", "month", "monthday", "site", "team", "decision", "runs1", "runs2"))Stack Overflow用户
发布于 2022-04-02 15:09:20
我不确定这是否是允许您使用多个分隔符进行分离的现有函数,因此我只是将所有分隔符替换为@,以使separate工作。
library(tidyverse)
df %>%
mutate(game = gsub("\\.\\s|,\\s|\\s+|-", "@", game) %>%
gsub("\\(|\\)|#", "", .)) %>%
separate(game,
into = c("year", "day", "month", "monthday", "site", "team", "decision", "runs1", "runs2"),
sep = "@")
# A tibble: 5 × 10
year day month monthday site team decision runs1 runs2 pitcher
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 2021 Mon Apr 5 at PHI L 3 5 deGrom
2 2020 Fri Jul 24 vs ATL W 1 0 deGrom
3 2019 Thu Mar 28 at WSN W 2 0 deGrom
4 2018 Thu Mar 29 vs STL W 9 4 Syndergaard
5 2017 Mon Apr 3 vs ATL W 6 0 SyndergaardStack Overflow用户
发布于 2022-04-02 15:09:36
我们可以使用extract来捕获组中的子字符串
library(dplyr)
library(tidyr)
df %>%
extract(game, into = c("year", "day", "month", "monthday", "site",
"team", "decision", "runs1", "runs2"),
"^(\\d{4})\\.\\s+(\\w+),\\s+(\\w+)\\s+(\\d+)\\s+(\\w+)\\s+(\\w+)\\s+(\\w+)\\s+\\((\\d+)-(\\d+)\\).*", convert = TRUE)-output
# A tibble: 5 × 10
year day month monthday site team decision runs1 runs2 pitcher
<int> <chr> <chr> <int> <chr> <chr> <chr> <int> <int> <chr>
1 2021 Mon Apr 5 at PHI L 3 5 deGrom
2 2020 Fri Jul 24 vs ATL W 1 0 deGrom
3 2019 Thu Mar 28 at WSN W 2 0 deGrom
4 2018 Thu Mar 29 vs STL W 9 4 Syndergaard
5 2017 Mon Apr 3 vs ATL W 6 0 Syndergaard或使用separate
df %>%
separate(col = game, into = c("year", "day", "month", "monthday",
"site", "team", "decision", "runs1", "runs2"),
sep = "\\s*[.,\\(\\)-]\\s*|\\s+", remove = TRUE, convert = TRUE)-output
# A tibble: 5 × 10
year day month monthday site team decision runs1 runs2 pitcher
<int> <chr> <chr> <int> <chr> <chr> <chr> <int> <int> <chr>
1 2021 Mon Apr 5 at PHI L 3 5 deGrom
2 2020 Fri Jul 24 vs ATL W 1 0 deGrom
3 2019 Thu Mar 28 at WSN W 2 0 deGrom
4 2018 Thu Mar 29 vs STL W 9 4 Syndergaard
5 2017 Mon Apr 3 vs ATL W 6 0 Syndergaard页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71718525
复制相关文章
相似问题
腾讯云开发者
