
如何根据R中的多列进行总结?
如何根据R中的多列进行总结?
提问于 2022-04-03 23:08:29
我想根据“年份”、“月份”和"subdist_id“列总结数据集。对于每一个subdist_id,我想得到11,12,1,2个月的“降雨量”平均值,但是是不同年份的平均值。例如,对于subdist_id 81,2004年的平均降雨量将是2004年的11个月、12个月和2005年的第1个月的平均降雨量。
我不知道怎么做,虽然我在网上搜索严格。
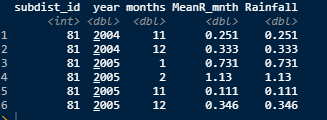
回答 3
Stack Overflow用户
回答已采纳
发布于 2022-04-04 00:20:44
关于@Bloxx的回答,并包含了我的评论:
# Set up example data frame:
df = data.frame(year=c(rep.int(2004,2),rep.int(2005,4)),
month=((0:5%%4)-2)%%12+1,
Rainfall=seq(.5,by=0.15,length.out=6))现在使用mutate创建year2变量:
df %>% mutate(year2 = year - (month<3)*1) # or similar depending on the problem specs现在应用groupby/概括操作:
df %>% mutate(year2 = year - (month<3)*1) %>%
group_by(year2) %>%
summarise(Rainfall = mean(Rainfall))Stack Overflow用户
发布于 2022-04-03 23:21:48
让我们假设您的数据集称为df。这就是你要找的吗?
df %>% group_by(subdist_id, year) %>% summarise(Rainfall = mean(Rainfall))Stack Overflow用户
发布于 2022-04-04 01:25:00
我认为你可以这么做:
df %>% filter(months %in% c(1,2,11,12)) %>%
group_by(subdist_id, year=if_else(months %in% c(1,2),year-1,year)) %>%
summarize(meanRain = mean(Rainfall))输出:
subdist_id year meanRain
<dbl> <dbl> <dbl>
1 81 2004 0.611
2 81 2005 0.228输入:
df = data.frame(
subdist_id = 81,
year=c(2004,2004, 2005, 2005, 2005, 2005),
months=c(11,12,1,2,11,12),
Rainfall = c(.251,.333,.731,1.13,.111,.346)
)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71730521
复制相关文章
相似问题
腾讯云开发者
