
TargetWrite/IorD控制线在多周期MIPS处理器上做什么?
我们学习了所有的主要细节,控制线和MIPS芯片的一般功能,在单周期和流水线。
但是,在多周期控制线是不相同的,除了其他的变化。
具体来说,TargetWrite (ALUout)和IorD控制线实际上修改了什么?根据我的分析,TW似乎修改了PC所指向的位置,这取决于它接收到的比特(对于跳转、分支或标准移动到下一行).我是不是遗漏了什么?
另外,IorD行到底是做什么的?我看了这两门课程的教科书:参见Mips Run and the Computer Architecture: Patterson和Hennessy的定量方法,这两本书似乎没有提到这些台词。
回答 1
Stack Overflow用户
发布于 2022-04-06 23:04:45
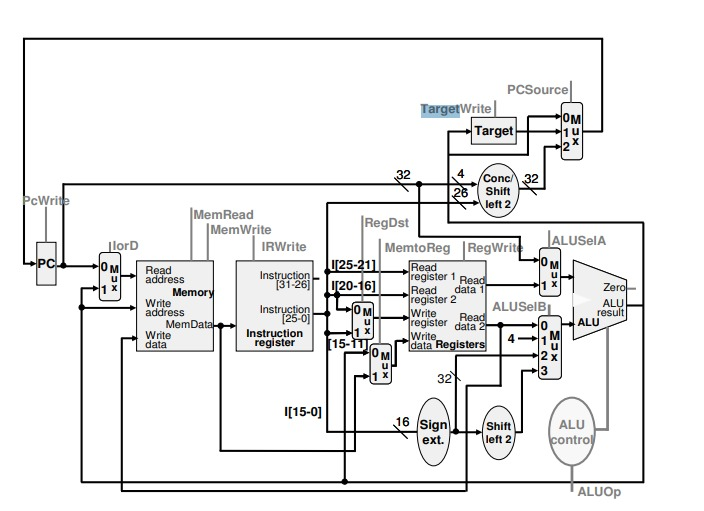
首先,让我们注意,这个框图没有单独的指令存储器和数据存储器。这意味着它要么有一个统一的高速缓存,要么直接进入内存。大多数用于MIPS的其它框图都将有单独的专用指令存储器(. )和数据存储器( cache )。其优点是处理器可以并行读取指令和读写数据。在多周期处理器的简单版本中,很可能不需要并行读取指令和数据,因此统一缓存简化了硬件。
因此,IorD所做的是为提供给内存的地址选择源--确定它是在对指令执行取取周期,还是对数据进行读/写。
当IorD=0然后PC提供要读取的地址(即指令获取),以及当IorD=1然后为数据操作提供读/写数据的地址时,ALU正在计算基+位移寻址模式:Reg[rs] + SignExt32(imm16)作为用于数据读写操作的有效地址。
此外,让我们注意,这个方框图不包含一个单独的加法器,用于将PC增加4,而大多数其他方框图则是这样。查找最初几个MIPS单周期数据路径图像中的任何一个,您将看到用于该PC增量的专用加法器。使用专用加法器可以使PC与ALU所做的操作并行递增,而省略该专用加法器则意味着主ALU必须执行PC的增量。然而,这可能会将晶体管保存在一个简单版本的多循环实现中,而ALU并不是每个周期都在使用,因此可以在其他情况下使用。
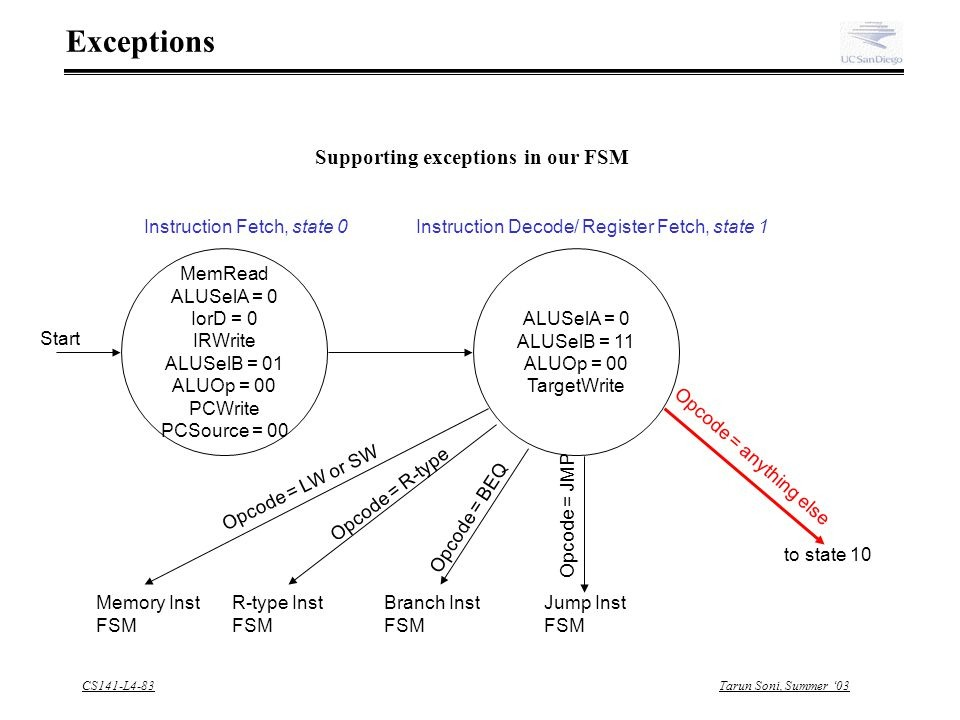
由于Target有一个控件TargetWrite,我们可以假定这是一个内部寄存器,它可能用于缓冲预期的分支目标地址,例如,如果在一个周期中计算分支目标,最后在另一个周期中使用。
(我认为这可能是为了缓冲分支延迟时隙实现(因为这些分支延迟了一条指令),但如果是这样的话,J型指令也会通过Target,而它们不会。
因此,在我看来,这个多周期处理器的机器是用来处理分支指令的,比如beq,它必须:
从PC + 4
- compute计算下一个顺序的
PC地址,从(PC+4) + SignExt32(imm32)
- compute的分支目标地址,分支条件(
Reg[rs] == Reg[rt]?)
但是计算它们的顺序是什么呢?从状态0的控制信号中可以清楚地看到:首先计算PC+4,然后将其写回PC,以处理所有的指令(即分支,不管是否使用分支)。
在我看来,在下一个周期中,(PC+4) + SignExt32(imm16)似乎是被计算出来的(通过重用当前在PC寄存器中的以前的PC+4 --这个结果存储在Target中以缓冲该值,因为它还不知道是否使用了分支)。在下一个周期中,rs和rt的内容是相等的,如果相同,则应该取分支,所以PCSource=1, PCWrite=1从缓冲区中选择Target来更新PC,如果没有,则选择Target,因为PC已经更新为PC+4,PC+4表示(PCWrite=0, PCSource=don't care)下一条指令的开始。在这两种情况下,下一条指令都以PC所持有的地址运行。
或者,由于处理器是多循环的,计算的顺序可以是:计算PC+4并存储到PC. 中计算分支条件,并决定接下来运行什么样的循环,即对于未接受的条件,直接进入下一个指令获取周期(在PC中有PC+4 ),或者,对于获取的分支条件,计算(PC+4) + SignExt32(imm16)并将其放入PC中,然后继续下一个指令获取周期。
这种替代方法将需要对分支的周期/状态进行动态更改,因此会在某种程度上使多循环状态机复杂化,而且也不需要缓冲分支Target -因此我认为前者比这个替代更有可能。
https://stackoverflow.com/questions/71773102
复制相似问题
腾讯云开发者
