
如何在不平衡的二进制分类项目中使用"is_unbalance“和"scale_pos_weight”参数(80:20)
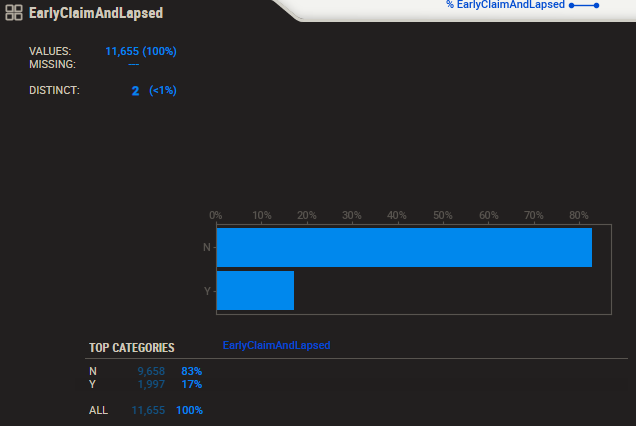
我目前有一个不平衡的数据集,如下图所示:
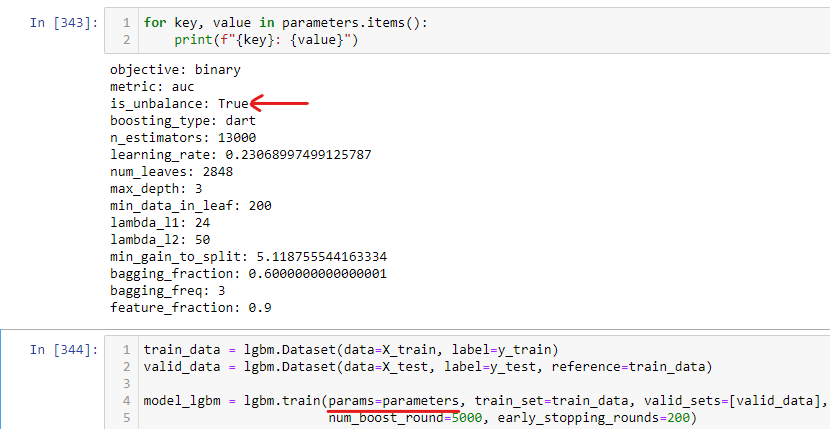
然后,我使用'is_unbalance‘参数,在训练LightGBM模型时将它设置为True。下面的图表显示了我如何使用这个参数。
使用本机API:的示例
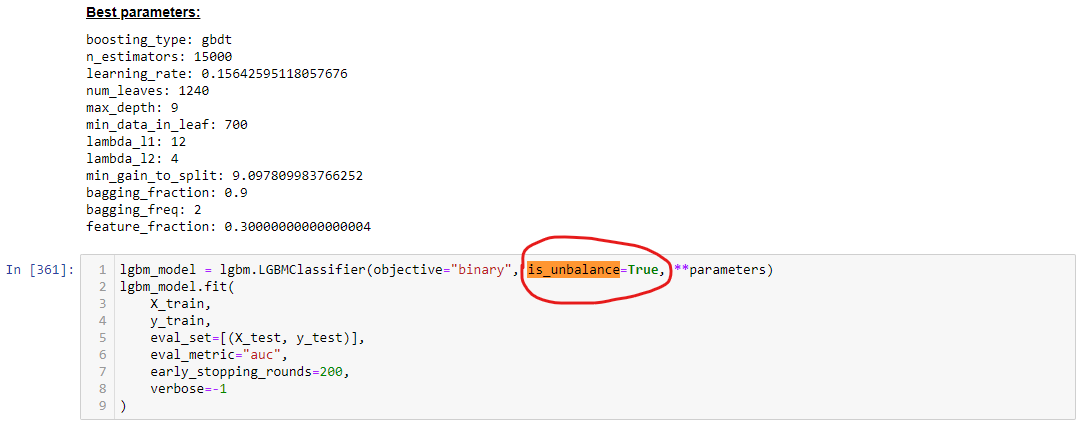
使用sckit-learnAPI:的示例
我的问题是:
is_unbalance
- Or
- 是应用
is_unbalance参数正确的方法吗?
- 如何使用
scale_pos_weight代替
- ,我应该使用SMOTE技术来平衡数据集,比如SMOTE-ENN
E 222或SMOTE+TOME
谢谢!
回答 1
Stack Overflow用户
发布于 2022-04-19 02:38:52
这个答案可能对您提出关于is_unbalance:Use of 'is_unbalance' parameter in Lightgbm的问题有好处。
您不一定不正确地使用is_unbalance,但是sample_pos_weight会更好地控制少数和多数类的权重。
在这个链接中,有一个关于scale_pos_weight使用的很好的解释:https://stats.stackexchange.com/questions/243207/what-is-the-proper-usage-of-scale-pos-weight-in-xgboost-for-imbalanced-datasets
基本上,scale_pos_weight允许为少数类设置一个可配置的权重,作为目标变量。关于这个主题的一个很好的讨论是在这里https://discuss.xgboost.ai/t/how-does-scale-pos-weight-affect-probabilities/1790/4。
关于SMOTE,我不能提供关于它的理论证明,但是考虑到我的经验,每次我尝试用它来提高任何使用SMOTE的模型性能时,它都失败了。
更好的方法可能是仔细决定必须优化哪个度量。更好的衡量不平衡问题的指标是F1评分和回忆。一般来说,AUC和准确性将是一个糟糕的选择。此外,在搜索超参数时,-micro和加权度量是很好的客观度量)
机器学习掌握提供了关于微观、宏和加权度量的良好解释和实现代码:https://machinelearningmastery.com/precision-recall-and-f-measure-for-imbalanced-classification/
https://stackoverflow.com/questions/71838896
复制相似问题
腾讯云开发者
