
PyTorch中的早期停止
PyTorch中的早期停止
提问于 2022-04-25 11:42:30
我试图实现一个早期停止功能,以避免我的神经网络模型过于适合。我很确定逻辑是好的,但出于某种原因,它不起作用。我希望当验证损失大于某个时期的训练损失时,早期停止函数返回True。但是它总是返回假的,即使验证损失比训练损失大得多。请问你能看到问题出在哪里吗?
早期停止功能
def early_stopping(train_loss, validation_loss, min_delta, tolerance):
counter = 0
if (validation_loss - train_loss) > min_delta:
counter +=1
if counter >= tolerance:
return True在训练期间调用函数
for i in range(epochs):
print(f"Epoch {i+1}")
epoch_train_loss, pred = train_one_epoch(model, train_dataloader, loss_func, optimiser, device)
train_loss.append(epoch_train_loss)
# validation
with torch.no_grad():
epoch_validate_loss = validate_one_epoch(model, validate_dataloader, loss_func, device)
validation_loss.append(epoch_validate_loss)
# early stopping
if early_stopping(epoch_train_loss, epoch_validate_loss, min_delta=10, tolerance = 20):
print("We are at epoch:", i)
break编辑:培训和验证损失:
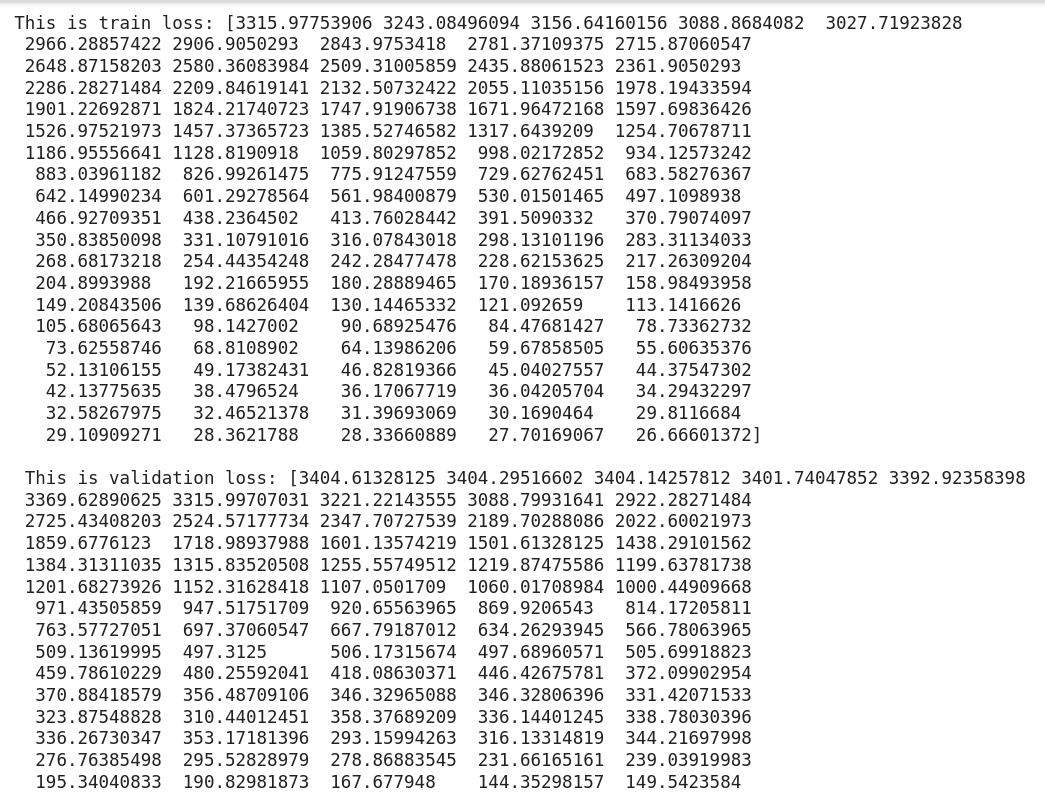
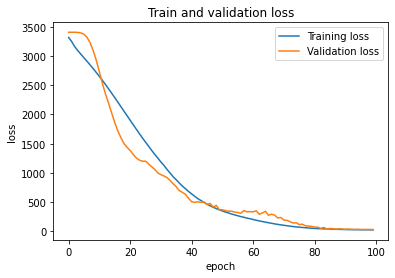
EDIT2:
def train_validate (model, train_dataloader, validate_dataloader, loss_func, optimiser, device, epochs):
preds = []
train_loss = []
validation_loss = []
min_delta = 5
for e in range(epochs):
print(f"Epoch {e+1}")
epoch_train_loss, pred = train_one_epoch(model, train_dataloader, loss_func, optimiser, device)
train_loss.append(epoch_train_loss)
# validation
with torch.no_grad():
epoch_validate_loss = validate_one_epoch(model, validate_dataloader, loss_func, device)
validation_loss.append(epoch_validate_loss)
# early stopping
early_stopping = EarlyStopping(tolerance=2, min_delta=5)
early_stopping(epoch_train_loss, epoch_validate_loss)
if early_stopping.early_stop:
print("We are at epoch:", e)
break
return train_loss, validation_loss回答 2
Stack Overflow用户
回答已采纳
发布于 2022-04-25 12:12:19
实现的问题是,每当您调用early_stopping()时,计数器就会用0重新初始化。
下面是使用面向对象的方法使用__call__()和__init__()的工作解决方案:
class EarlyStopping():
def __init__(self, tolerance=5, min_delta=0):
self.tolerance = tolerance
self.min_delta = min_delta
self.counter = 0
self.early_stop = False
def __call__(self, train_loss, validation_loss):
if (validation_loss - train_loss) > self.min_delta:
self.counter +=1
if self.counter >= self.tolerance:
self.early_stop = True就这么说吧:
early_stopping = EarlyStopping(tolerance=5, min_delta=10)
for i in range(epochs):
print(f"Epoch {i+1}")
epoch_train_loss, pred = train_one_epoch(model, train_dataloader, loss_func, optimiser, device)
train_loss.append(epoch_train_loss)
# validation
with torch.no_grad():
epoch_validate_loss = validate_one_epoch(model, validate_dataloader, loss_func, device)
validation_loss.append(epoch_validate_loss)
# early stopping
early_stopping(epoch_train_loss, epoch_validate_loss)
if early_stopping.early_stop:
print("We are at epoch:", i)
break示例:
early_stopping = EarlyStopping(tolerance=2, min_delta=5)
train_loss = [
642.14990234,
601.29278564,
561.98400879,
530.01501465,
497.1098938,
466.92709351,
438.2364502,
413.76028442,
391.5090332,
370.79074097,
]
validate_loss = [
509.13619995,
497.3125,
506.17315674,
497.68960571,
505.69918823,
459.78610229,
480.25592041,
418.08630371,
446.42675781,
372.09902954,
]
for i in range(len(train_loss)):
early_stopping(train_loss[i], validate_loss[i])
print(f"loss: {train_loss[i]} : {validate_loss[i]}")
if early_stopping.early_stop:
print("We are at epoch:", i)
break输出:
loss: 642.14990234 : 509.13619995
loss: 601.29278564 : 497.3125
loss: 561.98400879 : 506.17315674
loss: 530.01501465 : 497.68960571
loss: 497.1098938 : 505.69918823
loss: 466.92709351 : 459.78610229
loss: 438.2364502 : 480.25592041
We are at epoch: 6Stack Overflow用户
发布于 2022-09-13 14:17:15
尽管@KarelZe's response充分而优雅地解决了您的问题,但我想提供一个可以说更好的替代早期停止标准。
您的早期停止标准是基于验证损失与培训损失的偏离程度(以及持续时间)。当验证损失确实在减少,但通常离训练损失还不够近时,这种情况就会中断。训练模型的目的是鼓励有效损失的减少,而不是减少训练损失和验证损失之间的差距。
因此,我认为,一个更好的早期停止标准将是观察验证损失的趋势,即,如果培训没有导致降低验证损失,那么就终止它。下面是一个实现示例:
class EarlyStopper:
def __init__(self, patience=1, min_delta=0):
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.min_validation_loss = np.inf
def early_stop(self, validation_loss):
if validation_loss < self.min_validation_loss:
self.min_validation_loss = validation_loss
self.counter = 0
elif validation_loss > (self.min_validation_loss + self.min_delta):
self.counter += 1
if self.counter >= self.patience:
return True
return False下面是你如何使用它的方法:
early_stopper = EarlyStopper(patience=3, min_delta=10)
for epoch in np.arange(n_epochs):
train_loss = train_one_epoch(model, train_loader)
validation_loss = validate_one_epoch(model, validation_loader)
if early_stopper.early_stop(validation_loss):
break页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71998978
复制相关文章
相似问题
腾讯云开发者
