
使用公司名称进行不平衡的多类分类
下面我有一个分类场景,在这个场景中,我得到了一个非常低的F1、精确性、召回和其他度量标准。
- Target是多类的(大约200个类),它是高度不平衡的
- I只使用公司名称作为分类器(多数为1-2个单词,最大为8个单词),没有其他字段(如描述等),使用
- 训练数据~ 100k+的数字字符和特殊字符以及删除终止词的
- I的处理资源非常少(这就是为什么当我尝试使用data、distance_smote等过采样技术时,我总是会收到内存错误)
H 111尝试使用不同的向量化//标记器,如word2vec、tfidf、快速文本、bert、roberta、等等,但
尝试使用(和微调)不同的算法(网络、svm、树、增强等),但都没有效果。I也做了对成本敏感的学习(使用课堂权重),但这只会降低我的分数。
尝试了我所知道的所有选项,但分数没有增加。您可以在这里推荐其他选项吗?或者您认为流程的任何部分可能是错误的/被丢弃的?谢谢!
目标标签的分布:
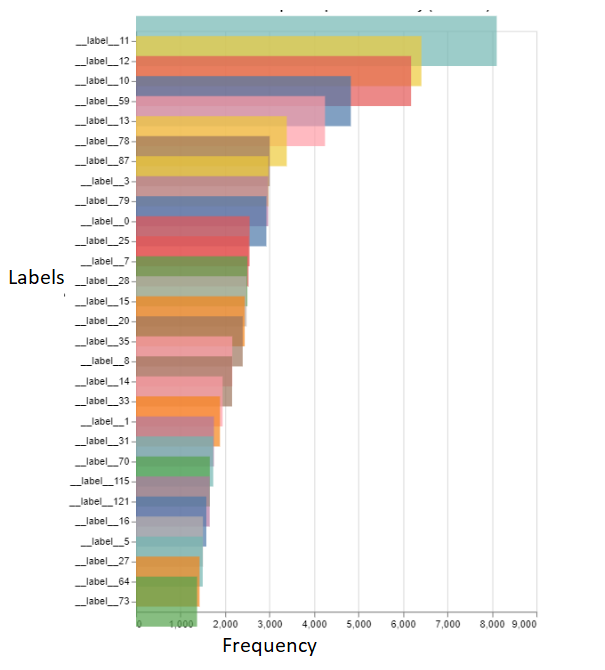
样本观测
回答 1
Stack Overflow用户
发布于 2022-04-28 15:02:08
根本不可能知道“埃克森”是一家石油公司,“苹果”是一家电脑公司,“McDonalds”是一家快餐连锁店,只是从他们的公司名称来看。
即使你有一份世界上每一家公司的名单,按名称和类型分列,也不足以对最后3家公司进行扣减。只有其他外部信息--比如关于它们的几句话或其他数据--才能对它们进行分类。
事实上,虽然公司名称有时会描述其确切的商业领域,但它们往往是完全武断的,因为这给了它们更多的自由,可以跨越许多产品/服务,或者创建自己与该名称的独特关联(又名品牌)。
因此,我强烈怀疑您的(未显示的)名称&(未显示)标签对于您所使用的数据太武断,无法很好地完成您正在尝试的任务。
是否有一个真实的情况,一个人将只有一个公司名称-没有其他信息,或研究选项-并受益于正确猜测的班级?如果是这样的话,有关情况的更多细节可能有助于提出更具体的战术建议。但主要是这样的建议:获取更丰富的分类目标数据。
通过更好的预处理/特征提取,您可能会从公司命名的模糊趋势中挤出更多的东西。您可能希望保留数字,特殊字符,和标点符号的某种形式,因为它们可能包括额外的轻微提示。使用子词(字符n-克)也可能会显示一些共享的词根,甚至在化名中也是如此。
https://stackoverflow.com/questions/72032366
复制相似问题
腾讯云开发者
