
如何将文本pdf更改为utf-8编码?
我有一堆正确显示西里尔字母的pdfs。但是如果我复制并粘贴他们的文字,就会产生胡言乱语。
然后,我使用保存函数从okular将pdf转换为文本文件,并发现编码是WINDOWS-1251,这是一个古老的西里尔编码。转换后,它UTF-8,西里尔的显示正确。
文件的一个示例链接是https://cdn.esis.edu.mn/cover/01/01_mongol_khel.pdf。
有没有办法将pdfs转换成编码的UTF-8,以便我可以复制、粘贴和搜索?
解决了
使用@iPDFdev提供的信息,我设法解决了这个问题。
对于可能遇到类似问题的人,我将Windows1251放在https://www.compart.com/en/unicode/charsets/windows-1251的UTF-8表中,并在https://github.com/pymupdf/PyMuPDF/issues/530上修改了代码。我完全无视旧的Unicode地图,并在所有页面上添加了用于所有字体的西里尔字母地图。
import fitz
import re
doc = fitz.open(inputFileName)
new = '1 beginbfrange\n<c0> <ff> <0410>\nendbfrange'
for pno in range(doc.page_count):
font_tuples = doc.get_page_fonts(2)
for font_tuple in font_tuples:
for line in doc.xref_object(font_tuple[0]).splitlines():
line = line.strip()
if line.startswith("/ToUnicode"):
stream_id = int(line.split()[1])
old_stream_decoded = doc.xref_stream(stream_id).decode()
new_stream_decoded = re.sub('[0-9]+? beginbfrange.*endbfrange', new, old_stream_decoded, flags=re.DOTALL)
new_stream_encoded = new_stream_decoded.encode()
doc.update_stream(stream_id, new_stream_encoded)
doc.save(outputFileName)回答 2
Stack Overflow用户
发布于 2022-05-04 06:54:07
CID(字符ids)可以使用Windows 1251编码正确地(手动)转换为西里尔字母。
但是PDF不支持这种编码,字体上的ToUnicode cmap构建得不正确。它还假设在使用Unicode值时使用Windows1251编码。
例如:CID0xCC用于显示西里尔字母EM (U+041C)。内部字体编码将0xCC映射到表示U+041C的字形(字符图像),从而直观地得到正确的字母。
但是,对于文本提取,您必须提供一个ToUnicode cmap,它告诉每个id代表什么Unicode字符。因此,ToUnicode cmap应该包括像这个0xCC -> U+041C这样的条目,但是文件中的ToUnicode cmap包含这个条目0xCC -> U+00CC,它不是西里尔字母EM。
顺便说一句,0xCC使用Windows1251编码映射到U+041C,但是PDF处理器无法知道这一点。
Stack Overflow用户
发布于 2022-05-04 13:12:39
使用

poppler-22.04.0\Library\bin>pdftotext -layout -f 1 -l 1 -enc ISO-8859-9 encoded.pdf -响应,只使用布局的第一页尝试似乎表明存在一些编码问题,但这是一个粗略的编程输出,也许可以通过FnR或代码调整加以改进。
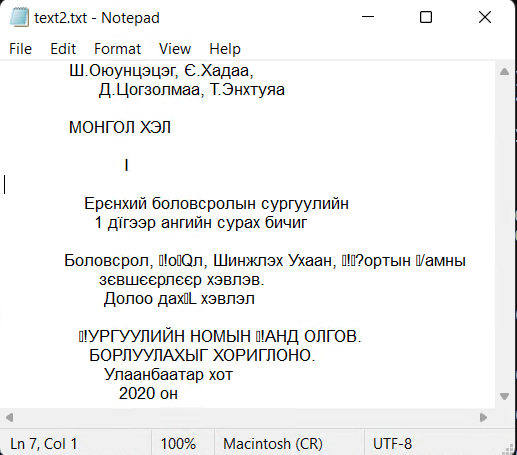
Ш.Оунццг, Є.Хадаа,
Д.Цогзолмаа, Т.нхтуяа
МОНГОЛ ХЛ
I
Еєнхий боловсолын сугуулийн
1 дїг ангийн суах бичиг
Боловсол, ол, Шинжлх Ухаан, отын амны
зєвшєєлєє хвлв.
Долоо дах хвлл
УГУУЛИЙН НОМЫН АНД ОЛГОВ.
БОЛУУЛАХЫГ ХОИГЛОНО.
Улаанбаата хот
2020 он另一种方法是尝试将此作为更有效的字符,但需要“去间距”。
pdftotext -layout -f 1 -l 1 -enc UTF-16 encoded.pdf -
Ш . О ю у н ц э ц э г , Є . Х а д а а ,
Д . Ц о г з о л м а а , Т . Э н х т у я а
М О Н Г О Л Х Э Л
I
Е р є н х и й б о л о в с р о л ы н с у р г у у л и й н
1 д ї г э э р а н г и й н с у р а х б и ч и г
Б о л о в с р о л , ! оQ л , Ш и н ж л э х У х а а н , !? о р т ы н / а м н ы
з є в ш є є р л є є р х э в л э в .
Д о л о о д а хL х э в л э л
! У Р Г У У Л И Й Н Н О М Ы Н ! А Н Д О Л Г О В .
Б О Р Л У У Л А Х Ы Г Х О Р И Г Л О Н О .
У л а а н б а а т а р х о т
2 0 2 0 о н但仍然需要用C代替C,用Я代替�/等。
注:在这两种情况下chcp 1251
https://stackoverflow.com/questions/72093721
复制相似问题
腾讯云开发者
