
Neo4j查询2种关系并在2种关系上计算聚合函数
Neo4j查询2种关系并在2种关系上计算聚合函数
提问于 2022-05-07 23:20:16
我有一个数据模型:
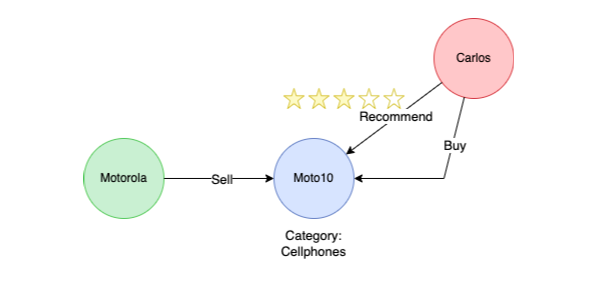
与节点:
- 客户端
- 供应商
- 产品
以及这些关系:
- 客户推荐的{资格} ->产品
- 客户购买->产品
- 销售商-销售->产品
我试图获得最畅销的产品,具有一般的资格,我实际上尝试了这样的查询:
MATCH (p:Product)<-[b:Buy]-(c:Client)
CALL{
WITH c, p
MATCH (c)-[r:Recommend]->(p)
RETURN avg(r.qualification) as average_qualification
}
RETURN p, c, count(b) as qty, average_qualification
ORDER BY qty DESC但是,查询为每个客户端的每个average_qualification返回一行(如下所示):
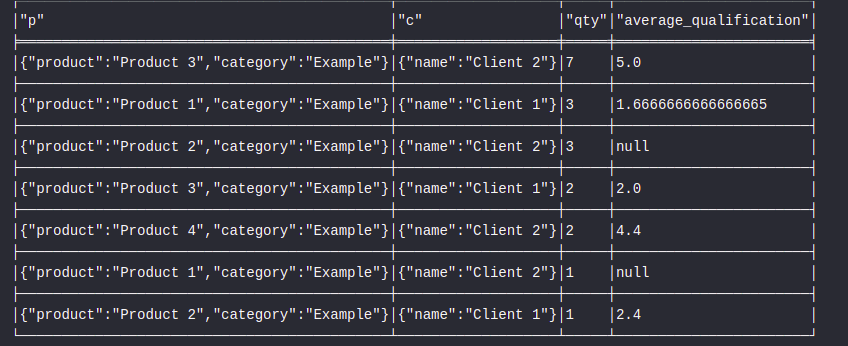
但是我希望对每个产品进行分组,因此它需要合并产品相同的行,因此,例如,行1和4将合并,average_qualification将是产品的average_qualification (不按客户资格划分)。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-05-08 13:32:22
你可以这样做:
MATCH (p:Product)<-[b:Buy]-(:Client)
WITH p, count(b) AS qty
MATCH (:Client)-[r:Recommend]->(p)
RETURN p, qty, avg(r.qualification) AS average_qualification
ORDER BY qty DESC在这个样本数据中:
MERGE (a:Client{name: 'A'})
MERGE (b:Client{name: 'B'})
MERGE (c:Client{name: 'C'})
MERGE (d:Client{name: 'D'})
MERGE (e:Client{name: 'E'})
MERGE (f:Vendor{key: 2})
MERGE (g:Vendor{key: 3})
MERGE (h:Vendor{key: 4})
MERGE (j:Product{key: 5})
MERGE (i:Product{key: 6})
MERGE (k:Product{key: 7})
MERGE (l:Product{key: 8})
MERGE (m:Product{key: 9})
MERGE (a)-[:Recommend{qualification: 4}]-(j)
MERGE (a)-[:Recommend{qualification: 4}]-(k)
MERGE (c)-[:Recommend{qualification: 3}]-(i)
MERGE (e)-[:Recommend{qualification: 3}]-(j)
MERGE (a)-[:Buy]-(k)
MERGE (a)-[:Buy]-(j)
MERGE (b)-[:Buy]-(l)
MERGE (d)-[:Buy]-(m)
MERGE (c)-[:Buy]-(i)
MERGE (d)-[:Buy]-(i)
MERGE (e)-[:Buy]-(i)
MERGE (e)-[:Buy]-(j)
MERGE (f)-[:Sell]-(i)
MERGE (f)-[:Sell]-(j)
MERGE (g)-[:Sell]-(k)
MERGE (h)-[:Sell]-(l)
MERGE (h)-[:Sell]-(m)将返回:
╒═════════╤═════╤═══════════════════════╕
│"p" │"qty"│"average_qualification"│
╞═════════╪═════╪═══════════════════════╡
│{"key":6}│3 │3.0 │
├─────────┼─────┼───────────────────────┤
│{"key":5}│2 │3.5 │
├─────────┼─────┼───────────────────────┤
│{"key":7}│1 │4.0 │
└─────────┴─────┴───────────────────────┘为了理解这个解决方案,以及为什么它不同于您的解决方案,我建议您阅读基数的概念。
不需要同时计算:buy和(:Client)。只保留其中的一个,并对其进行count,使我们能够完成第一个MATCH的产品列表,而不是一个客户列表。第二个MATCH也是如此,我们在r.qualification上使用avg,允许我们维护产品列表而不是推荐列表。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72157020
复制相关文章
相似问题
腾讯云开发者
