
如何根据空白区域或边缘检测OpenCV将图像分割成多个小图像?
如何根据空白区域或边缘检测OpenCV将图像分割成多个小图像?
提问于 2022-05-11 23:45:22
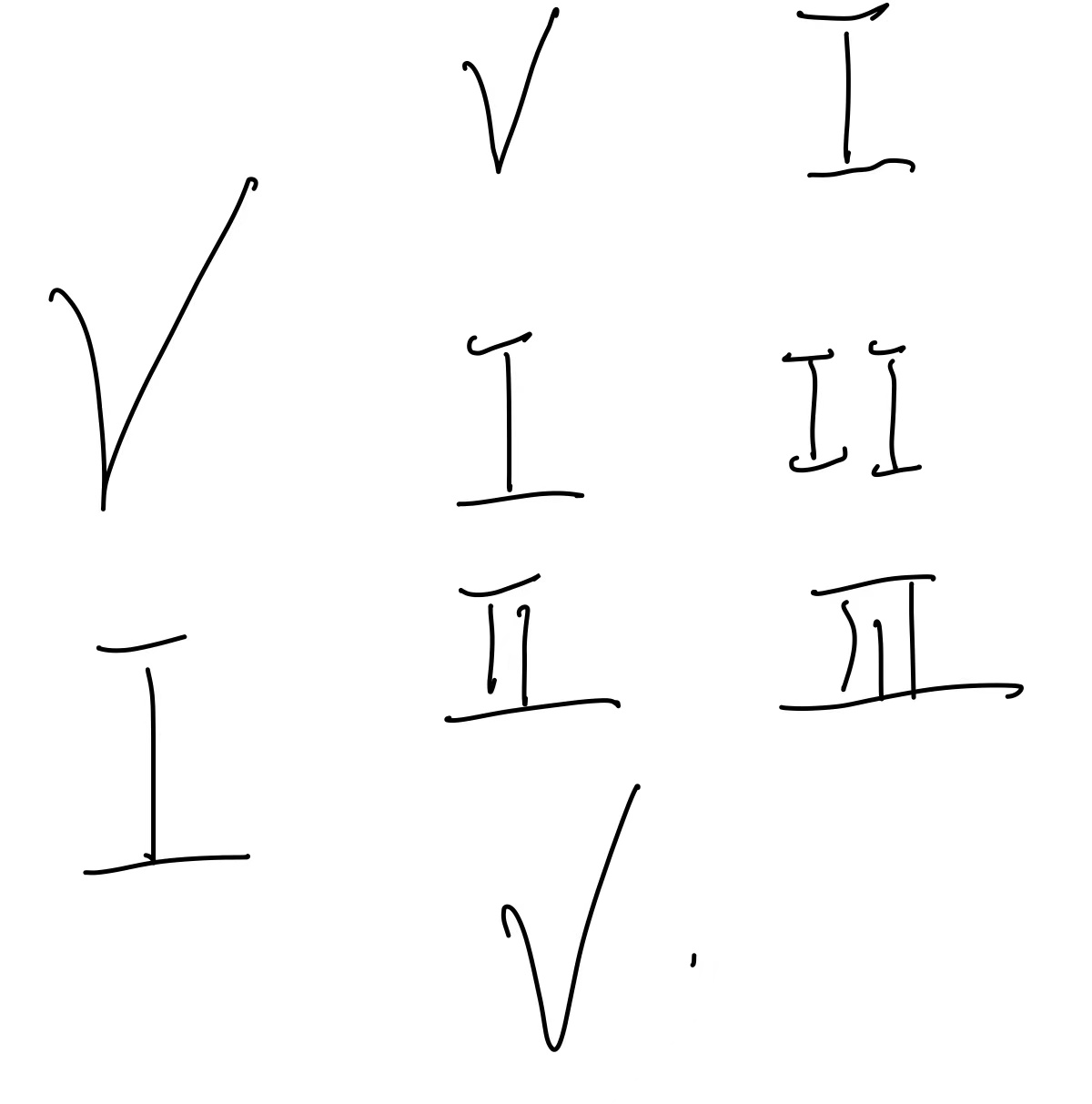
我有很多类似的图片。每个文本/罗马数字的大小可能不同,因为它是手写的。
如何将每个文本/罗马数字分别保存为.png格式?有9个文本有一个点。因此,输出应该分别是10或9图像。每个文本/罗马数字之间的空格是不同的。我应该根据精明的边缘或者其他更好的方法来裁剪它们吗?
我不知道这有多难,因为我是一个新手的简历。但我计划为我的项目这么做。
回答 1
Stack Overflow用户
发布于 2022-05-11 23:56:39
其主要思想是使用扩张将单个轮廓组合在一起,然后逐个裁剪。这里有一个简单的方法
检测到的ROIs以绿色突出显示
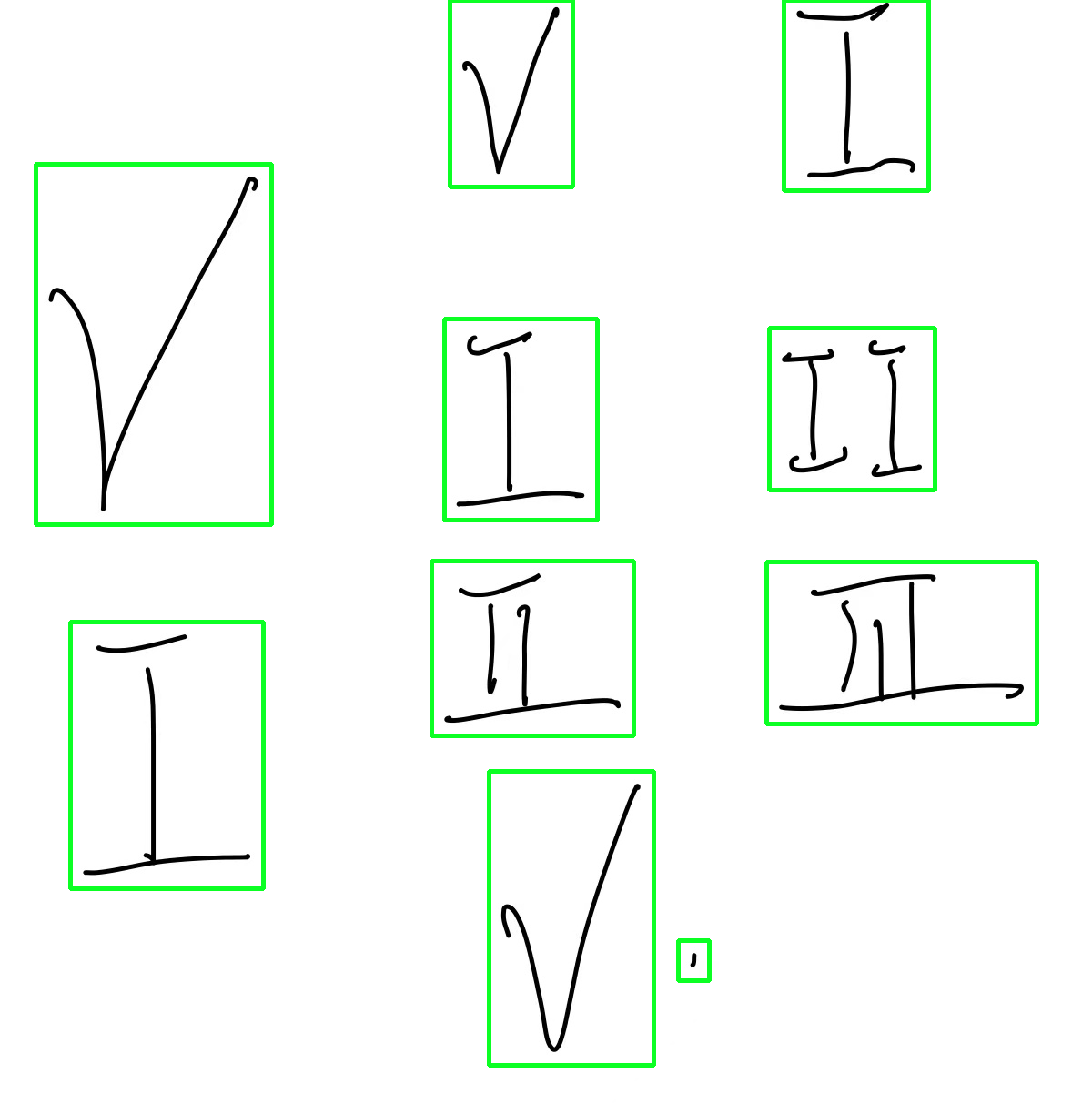
提取和保存ROIs

import cv2
# Load image, grayscale, Gaussian blur, Otsu's threshold, dilate
image = cv2.imread('1.jpg')
original = image.copy()
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5,5), 0)
thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (15,15))
dilate = cv2.dilate(thresh, kernel, iterations=2)
# Find contours, obtain bounding box coordinates, and extract ROI
cnts = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
image_number = 0
for c in cnts:
x,y,w,h = cv2.boundingRect(c)
cv2.rectangle(image, (x, y), (x + w, y + h), (36,255,12), 3)
ROI = original[y:y+h, x:x+w]
cv2.imwrite("ROI_{}.png".format(image_number), ROI)
image_number += 1
cv2.imshow('image', image)
cv2.imshow('thresh', thresh)
cv2.imshow('dilate', dilate)
cv2.waitKey() 页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72208696
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号