
nvidia-smi给出了一个码头容器内的错误。
当我从家里回到工作场所时,
- 有时无法在码头容器内与Nvidia GPU通信,尽管以前启动的利用GPU的进程运行良好。运行过程(通过Pytorch训练神经网络)不受断开的影响,但我不能启动一个新的进程。
nvidia-smi给出了Failed to initialize NVML: Unknown Error,torch.cuda.is_available()同样返回了False。
- I遇到了两个不同的案例:
当在主机上完成时,
nvidia-smi工作正常。在这种情况下,可以通过docker stop $MYCONTAINER重新启动码头容器,然后在主机docker stop $MYCONTAINER上重新启动docker start $MYCONTAINER来解决这种情况。
nvidia-smi不能在主机上工作,也不能在nvcc --version上工作,会引发Failed to initialize NVML: Driver/library version mismatch和Command 'nvcc' not found, but can be installed with: sudo apt install nvidia-cuda-toolkit错误。奇怪的是,目前的进程仍然运行良好。在这种情况下,重新安装驱动程序或重新启动机器可以解决problem.
问题。
然而,
- 需要停止所有当前进程。当我不应该停止当前进程时,它将不可用。
有人有解决这种情况的建议吗?
非常感谢。
(软件)
- Docker版本: 20.10.14,构建a224086
- OS: Ubuntu22.04
- Nvidia驱动程序版本:
- 版本: 11.6
(硬件)
超微细server
- Nvidia
- A5000 * 8
- (pic1) nvidia-smi不是在码头容器内工作,而是在主机上工作得很好。
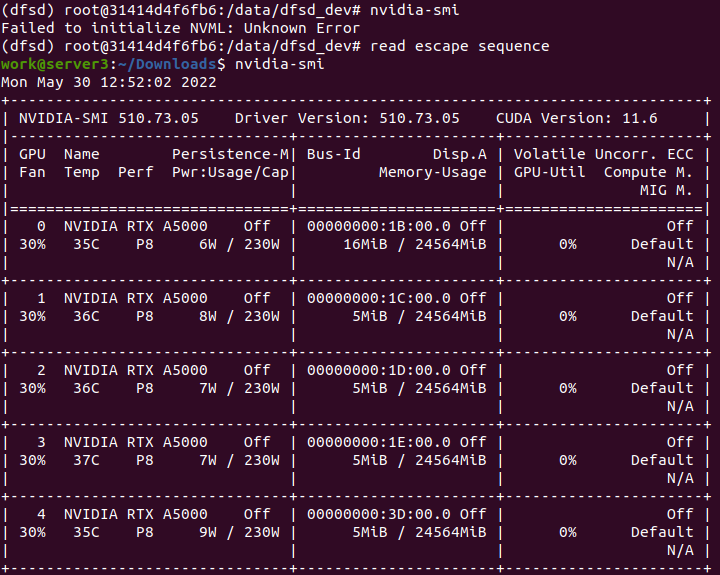
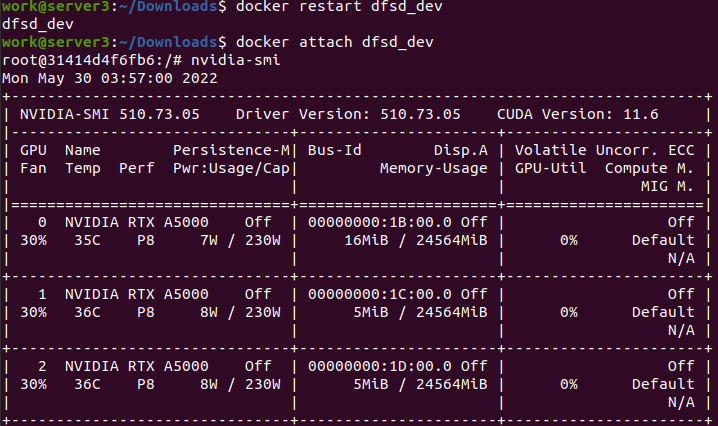
- (pic2) nvidia-smi在重新启动码头容器后工作,这就是我前面提到的
的情况1。
Stack Overflow用户
发布于 2022-09-03 15:35:22
关于Failed to initialize NVML: Unknown Error的问题和重新启动容器的问题,请查看此票证,并将您的系统/包信息张贴在那里:https://github.com/NVIDIA/nvidia-docker/issues/1671。
在票证上有一个解决办法,但是最好让其他人发布他们的配置来帮助解决这个问题。
将containerd.io降级为1.6.6,只要您在/etc/nvidia-容器-运行时/config.toml中指定no-cgroup= true,并指定像docker一样运行的设备--所有-gpus设备/dev/nvidia0: /dev /nvidia0 -设备/dev/nvidia-modeset:/dev/nvidia-modeset -设备/dev/nvidia-nvidia uvm-uvm设备/dev/nvidia-uvm tools:/dev/nvidia-uvm tools-/dev/nvidiactl:/dev/nvinvidiactl -rm -it nvidia/cuda:11.4.2-base-ubuntu18.04 bash
因此,sudo apt-get install -y --allow-downgrades containerd.io=1.6.6-1和sudo apt-mark hold containerd.io可以防止包被更新。因此,编辑配置文件,并将所有/dev/nvidia*设备传递给docker run。
对于Failed to initialize NVML: Driver/library version mismatch问题,这是由驱动程序更新引起的,但尚未重新启动。如果这是一台生产机器,我也会持有驱动程序包,以阻止它的自动更新。您应该能够从类似于sudo dpkg --get-selections "*nvidia*"的东西中找出包名。
https://stackoverflow.com/questions/72356527
复制相似问题
腾讯云开发者
