
如何替换PostgeSQL中字符串的所有可能子集
如何替换PostgeSQL中字符串的所有可能子集
提问于 2022-06-05 07:47:11
我在PostgreSQL中寻找一个代码块来替换列表中字符串的每一个可能的子集,我有一个同义词列表,如果我有一个名为"ABS“的字符串,并且我有一个私有和LTD的同义词,那么我希望我的输出是所有可能的组合的数组,例如
ABS PVT有限公司ABS私人有限公司ABS私人有限公司
对于我目前的方法,我得到了输出,但不是所有可能的组合,即ABS PVT有限公司,ABS私有有限公司。
我已经附加了我的当前代码
coalesce(array_agg(regexp_replace(stringtransformation('ABS PVT LTD', true),concat('\y',keyword,'\y'), syno)),ARRAY[]::text[])
from
synonyms s
where
keyword in (
select
unnest(
string_to_array(stringtransformation('ABS PVT LTD', true), ' ')
)
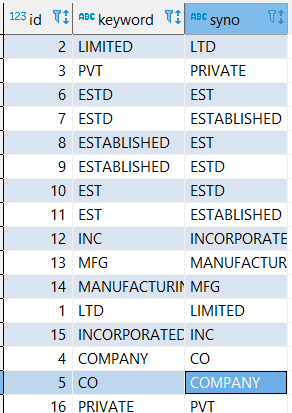
);这是我的同义词
回答 1
Stack Overflow用户
发布于 2022-06-05 21:26:04
也许有一种更简单的方法,但我会使用联合、连接和递归的组合。
这个CTE模拟了一个同义词表,每对只有一面:
with recursive synonyms_unidirectional (keyword, synonym) as (
values ('PVT', 'PRIVATE'),
('LTD', 'LIMITED')
), 将其与自身结合,以获得反向同义词:
synonyms as (
select keyword, synonym from synonyms_unidirectional
union
select synonym, keyword from synonyms_unidirectional
), 这将模拟一个保存公司名称的表:
company (id, company_name) as (
values (1, 'ABS PVT LTD')
), 将名称分成几行,并跟踪每个公司名称中有多少个单词:
words as (
select c.id, w.*, max(w.n) over (partition by id) as nwords
from company c
cross join lateral
regexp_split_to_table(c.company_name, '\s+') with ordinality as w(word, n)
),保存与双向同义词表(CTE)连接的每个原始单词和联合:
words_and_synonyms as (
select id, n, word as synonym, nwords
from words
union
select w.id, w.n, s.synonym, nwords
from words w
join synonyms s on s.keyword = w.word
)使用递归重建关键字和同义词的每一个可能的组合:
, rejoin as (
select id, n, array[synonym] as company_name, nwords
from words_and_synonyms
where n = 1
union all
select p.id, c.n, p.company_name||c.synonym, p.nwords
from rejoin p
join words_and_synonyms c
on c.id = p.id
and c.n = p.n + 1
)从数组中重构字符串,并只保留具有正确字数的行:
select id, array_to_string(company_name, ' ') as company_name
from rejoin
where n = nwords;结果:
┌────┬─────────────────────┐
│ id │ company_name │
├────┼─────────────────────┤
│ 1 │ ABS PRIVATE LTD │
│ 1 │ ABS PVT LTD │
│ 1 │ ABS PRIVATE LIMITED │
│ 1 │ ABS PVT LIMITED │
└────┴─────────────────────┘
(4 rows)db<>fiddle https://dbfiddle.uk/?rdbms=postgres_14&fiddle=b1c6936e2eedf10d557758e29cf15d12
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72505628
复制相关文章
相似问题
腾讯云开发者
