
如何将数据框架按多个不同类别进行子集?
如何将数据框架按多个不同类别进行子集?
提问于 2022-06-08 04:33:17
我正在尝试将数据框架划分为多个类别。
例如-我的数据集看起来类似于
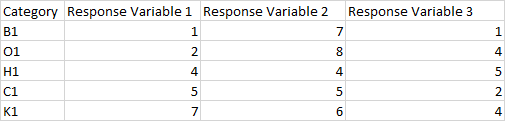
我想要做的是对这个数据框架进行子集,所以我只有来自类别B1、O1和H1以及响应变量1和3的样本,而不必计算行或列(实际的数据集相当大)。
我尝试用以下代码来完成这个任务:
mydata <- subset(df,
Category == ("B1", "O1", "H1"),
select = c(Response variable 1, Response variable 3))但是,我一直收到以下错误:
drop && length(x) == 1L中的
错误:“x&y”中无效的“x”类型
只是想知道像这样对数据集进行子集的最佳方法是什么?
回答 2
Stack Overflow用户
发布于 2022-06-08 06:57:52
这是tidyverse (特别是{dplyr} )真正发光的那种操作。您可以将filter()和select()函数组合在一起。
## create an example data.frame
df <- data.frame(Category = c("B1", "O1", "H1", "C1", "K1"),
RV1 = c(1,2,4,5,7),
RV2 = c(7,8,4,5,6),
RV3 = c(1,4,5,2,4))
## load the dplyr package
library(dplyr)
df %>%
filter(Category %in% c("B1", "O1", "H1")) %>%
select(RV1, RV3)
#> RV1 RV3
#> 1 1 1
#> 2 2 4
#> 3 4 5Stack Overflow用户
发布于 2022-06-10 04:29:09
对于Category,您需要使用%in%而不是== (正如注释中提到的那样)。您将得到该错误,因为==希望双方的项长度相等。例如,如果要执行rep(df$Category, 3) == c("B1", "O1", "H1"),则不会得到错误。这里您想要的是能够确定给定元素是否位于向量中,因此使用%in%将检查一个项是否在列表中(逻辑上的)。因此,subset将从该条件返回TRUE的行。然后,在select语句中,需要在全名周围使用引号。
mydata <- subset(df, Category %in% c("B1", "O1", "H1"),
select = c("Response variable 1", "Response variable 3"))输出
mydata
Response variable 1 Response variable 3
1 1 1
2 2 4
3 4 5数据
df <- structure(list(Category = c("B1", "O1", "H1", "C1", "K1"), `Response variable 1` = c(1,
2, 4, 5, 7), `Response variable 2` = c(7, 8, 4, 5, 6), `Response variable 3` = c(1,
4, 5, 2, 4)), class = "data.frame", row.names = c(NA, -5L))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72540104
复制相关文章
相似问题
腾讯云开发者
