
Azure数据工厂-运行脚本对拼花文件和输出作为拼花文件
Azure数据工厂-运行脚本对拼花文件和输出作为拼花文件
提问于 2022-06-08 14:53:59
在Azure Data中,我有一个管道,它是从内置的复制数据任务中创建的,它复制来自12个实体(活动、领导、联系等)的数据。从Dynamics (使用链接服务)并将内容输出为帐户存储中的parquet文件。这是每天运行,以文件夹结构为基础的日期。容器中的输出结构如下所示:
- Raw/CRM/2022/05/28/campaign.parquet
- Raw/CRM/2022/05/28/lead.parquet
- Raw/CRM/2022/05/29/campaign.parquet
- Raw/CRM/2022/05/29/lead.parquet
这只是一个例子,但是管道运行的每一年/月/日都有一个文件夹结构,我正在检索的12个实体中的每个实体都有一个parquet文件。
这涉及创建管道、源数据集和目标数据集。我修改了管道,将管道的运行日期/时间作为一个列添加到parquet文件中,称为RowStartDate (在下一个处理阶段我将需要它)
下一步是将数据处理到一个暂存区域,然后将其输出到容器中的另一个文件夹中。我的计划是创建12个脚本(一个用于竞选,一个用于领导,一个用于联系人等)。这基本上做到了以下几点:
/campaign.parquet
- selects /CRM/*/*/*使用通配符路径访问所有正确的文件--在某些情况下,RowStartDate)
- in需要
- 重命名列标题
- ,只需获取最新的数据(使用RowStartDate)
- in某些情况下,创建一个缓慢变化的维度,确保每行都有RowEndDate
通过使用OPENROWSET在上面的路径中使用通配符运行查询,我在SQL中找到了一些进展,但我认为我无法使用ADF中的SQL脚本将数据移动/处理到容器中的一个单独文件夹中。
我的问题是,我如何做到这一点(最好是在ADF管道中):
对于我的12个实体中的每个实体,按照我前面描述的逻辑访问容器中的每个事件/CRM//*/ statement
- Process . per
- --某种
- 的脚本将内容输出回容器中的不同文件夹(每个脚本将产生1个输出)
我试过:
使用Azure dataset的
- ,但是当我告诉它要使用哪个数据集时,我将它指向我在原始管道中创建的数据集--但是这个数据集中有数据集中的所有12个实体,数据流活动会产生错误:“参数‘cw_fileName不提供值”--但是当配置数据流以指定参数(它不在源设置、源选项、投影、优化或 Azure data Factory下面)时,我看不到任何位置。我试图添加一个脚本--但是在Synapse中试图连接到我的SQL脚本时--我不知道我的workspace
- using服务主键是一个笔记本数据库,我试图挂载我的容器,但是出现了一个错误:“在标准层中向数据库范围添加秘密”,所以proceed
- using Synapse不能这样做,但正如预期的那样,它希望在proceed
- using中找到东西,而我现在正试图将它们保存在容器中。
谁能给我指明正确的方向。我最好的方法是什么?如果是我上面描述过的问题,我该如何克服我所描述的问题呢?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-06-13 07:50:51
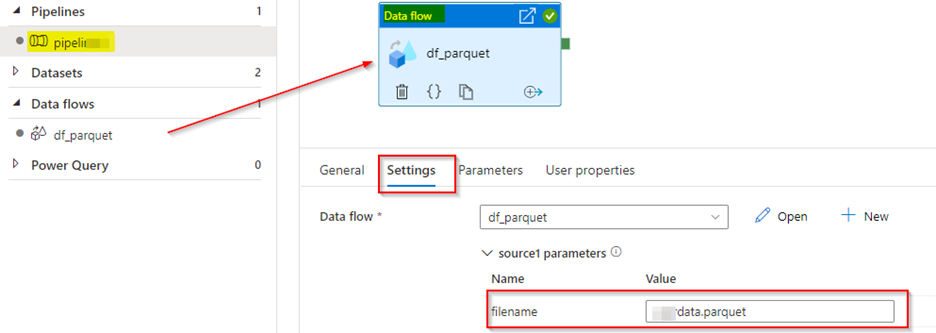
从管道data flow活动设置传递data flow数据集参数值。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72547903
复制相关文章
相似问题
腾讯云开发者
