
如何将数据从宽更改为长,并添加一个星期变量?
如何将数据从宽更改为长,并添加一个星期变量?
提问于 2022-06-14 12:02:47
我想用dplyr库将以下数据帧从wide转换为long,从而添加一个新列,该列的值为0到6(这些是周数)。
基本上,ID1应该在一个具有新名称AI_mean的新列中获取x1.AI_mean, x2.AI_mean, x3.AI_mean, x4.AI_mean, x5.AI_mean, x6.AI_mean, x7.AI_mean的值。ID2, ID3, and ID4和Xn.MAD_mean, Xn.SD_mean, and Xn.ENMO_t_mean也是如此。最后是一个新变量WEEK,它包含每个IDn的值0 to 6。
structure(list(PATIENT = c("ID1", "ID2", "ID3", "ID4"), X = c(720.5,
720.5, 720.5, 720.5), x1.time = c(NA_real_, NA_real_, NA_real_,
NA_real_), x1.AI_mean = c(0.490476892062554, 0.490476892062554,
0.70756243831039, 0.500081418561785), x1.MAD_mean = c(0.00679103139766459,
0.00679103139766459, 0.00954743428626949, 0.00710904629009617
), x1.SD_mean = c(0.0106151007507127, 0.0106151007507127, 0.015152755341205,
0.0112303076216956), x1.ENMO_t_mean = c(0.0274584728800568, 0.0274584728800568,
0.0103042219408169, 0.0312022382217336), x2.AI_mean = c(0.176041840541869,
0.176041840541869, 0.592412808880571, 0.35677297296871), x2.MAD_mean = c(0.00219051379797853,
0.00219051379797853, 0.00805673531422341, 0.00453736023712558
), x2.SD_mean = c(0.0042327545879746, 0.0042327545879746, 0.0140414178610565,
0.00925877414143479), x2.ENMO_t_mean = c(0.0167368725509965,
0.0167368725509965, 0.0227390281999353, 0.0155848050604389),
x3.AI_mean = c(0.196041545024115, 0.196041545024115, 0.655307840759778,
0.221302751464224), x3.MAD_mean = c(0.00265630445403654,
0.00265630445403654, 0.00874391858567126, 0.00312035180332525
), x3.SD_mean = c(0.00520681312926095, 0.00520681312926095,
0.0157667943293325, 0.00624832947258687), x3.ENMO_t_mean = c(0.0119919971714286,
0.0119919971714286, 0.0100238236393579, 0.00656607512069684
), x4.AI_mean = c(0.117134710729985, 0.117134710729985, 0.361142215576095,
0.152118386513676), x4.MAD_mean = c(0.00153368928913688,
0.00153368928913688, 0.00472008657879794, 0.00206572112752077
), x4.SD_mean = c(0.0030610465493998, 0.0030610465493998,
0.00871683182250033, 0.00425641902166748), x4.ENMO_t_mean = c(0.0206690781131853,
0.0206690781131853, 0.0164924536260057, 0.0322199920464069
), x5.AI_mean = c(0.152479968850333, 0.152479968850333, 0.372722877072248,
0.177229175029103), x5.MAD_mean = c(0.00218479624377481,
0.00218479624377481, 0.00487471442391749, 0.0024498723388947
), x5.SD_mean = c(0.00411993764019002, 0.00411993764019002,
0.00835039679052993, 0.00490289848155512), x5.ENMO_t_mean = c(0.0193947774446542,
0.0193947774446542, 0.0272692466077814, 0.0164903542931842
), x6.AI_mean = c(0.119878028436753, 0.119878028436753, 0.157829880732805,
0.1207450521664), x6.MAD_mean = c(0.00158146230736721, 0.00158146230736721,
0.0021877978464384, 0.00163733826134428), x6.SD_mean = c(0.00294818482781542,
0.00294818482781542, 0.0037086538389958, 0.00327129197883436
), x6.ENMO_t_mean = c(0.00917902093158174, 0.00917902093158174,
0.0162515614269202, 0.0208151667760968), x7.AI_mean = c(0.135059320114058,
0.135059320114058, 0.359440718946815, 0.130358911012721),
x7.MAD_mean = c(0.00195030841376017, 0.00195030841376017,
0.00404364526494212, 0.00182308928005729), x7.SD_mean = c(0.00370429514585471,
0.00370429514585471, 0.00767887188804178, 0.00351171698747009
), x7.ENMO_t_mean = c(0.021269549357265, 0.021269549357265,
0.0133371675149058, 0.0122713966971745)), row.names = c(NA,
-4L), class = c("tbl_df", "tbl", "data.frame"))编辑:
现在我使用了下面的代码来获取长格式表。但是,如何能够在同一数据格式中的新列中添加1,2,3,3,4,5,6,7到ID1和1,2,3,4,5,6,7到ID2等?
NEW <- Mean_patient_per_7_weeks[,c(1,4,8,12,16,20,24,28)]
AI_mean <- NEW %>%
pivot_longer(
cols = ends_with("mean"),
names_to = "AI_mean_month",
values_to = "AI_mean",
values_drop_na = TRUE
)
structure(list(PATIENT = c("ID1", "ID1", "ID1", "ID1", "ID1",
"ID1", "ID1", "ID2", "ID2", "ID2", "ID2", "ID2", "ID2", "ID2",
"ID3", "ID3", "ID3", "ID3", "ID3", "ID3", "ID3", "ID4", "ID4",
"ID4", "ID4", "ID4", "ID4", "ID4"), AI_mean_month = c("x1.AI_mean",
"x2.AI_mean", "x3.AI_mean", "x4.AI_mean", "x5.AI_mean", "x6.AI_mean",
"x7.AI_mean", "x1.AI_mean", "x2.AI_mean", "x3.AI_mean", "x4.AI_mean",
"x5.AI_mean", "x6.AI_mean", "x7.AI_mean", "x1.AI_mean", "x2.AI_mean",
"x3.AI_mean", "x4.AI_mean", "x5.AI_mean", "x6.AI_mean", "x7.AI_mean",
"x1.AI_mean", "x2.AI_mean", "x3.AI_mean", "x4.AI_mean", "x5.AI_mean",
"x6.AI_mean", "x7.AI_mean"), AI_mean = c(0.490476892062554, 0.176041840541869,
0.196041545024115, 0.117134710729985, 0.152479968850333, 0.119878028436753,
0.135059320114058, 0.490476892062554, 0.176041840541869, 0.196041545024115,
0.117134710729985, 0.152479968850333, 0.119878028436753, 0.135059320114058,
0.70756243831039, 0.592412808880571, 0.655307840759778, 0.361142215576095,
0.372722877072248, 0.157829880732805, 0.359440718946815, 0.500081418561785,
0.35677297296871, 0.221302751464224, 0.152118386513676, 0.177229175029103,
0.1207450521664, 0.130358911012721)), row.names = c(NA, -28L), class = c("tbl_df",
"tbl", "data.frame"))回答 1
Stack Overflow用户
回答已采纳
发布于 2022-06-14 14:10:07
请尝试以下代码:
library(tidyverse)
library(dplyr)
library(readr)
library(sjmisc)
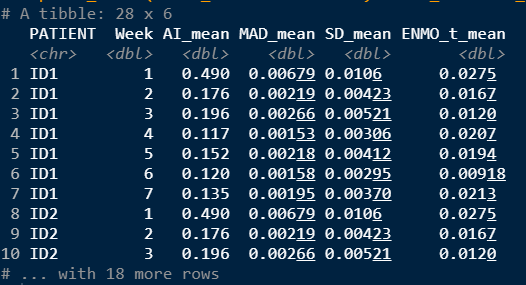
A %>%
pivot_longer(!c(PATIENT,X,x1.time), names_to = "Parameters", values_to = "AI_mean") %>%
mutate(Week = parse_number(Parameters),
MeanNames = case_when(grepl("AI", Parameters) ~ "AI_mean",
grepl("MAD", Parameters) ~ "MAD_mean",
grepl("SD", Parameters) ~ "SD_mean",
grepl("ENMO", Parameters) ~ "ENMO_t_mean")) %>%
select(PATIENT,Week,AI_mean,MeanNames) %>%
pivot_wider(names_from = MeanNames,values_from =AI_mean)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72616637
复制相关文章
相似问题
腾讯云开发者
