
两个领域中的大熊猫数量
两个领域中的大熊猫数量
提问于 2022-06-15 21:55:29
我正在试图找到包含两个字段的唯一值的数量。例如,一个典型的例子就是姓和名。我有一个数据框架。
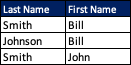
当我执行以下操作时,我只得到每一列的唯一字段数,在本例中为Last。不是合成物。
df[['Last Name','First Name']].nunique()谢谢!
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-06-15 23:03:44
IIUC,你可以用value_counts():
df[['Last Name','First Name']].value_counts().size
3另一个例子是,如果从包含一些dups的扩展数据框架开始:
Last Name First Name
0 Smith Bill
1 Johnson Bill
2 Smith John
3 Curtis Tony
4 Taylor Elizabeth
5 Smith Bill
6 Johnson Bill
7 Smith Bill然后,value_counts()根据唯一的复合姓氏给出计数:
df[['Last Name','First Name']].value_counts()
Last Name First Name
Smith Bill 3
Johnson Bill 2
Curtis Tony 1
Smith John 1
Taylor Elizabeth 1然后,该帧的长度将给出唯一的复合姓氏数:
df[['Last Name','First Name']].value_counts().size
5Stack Overflow用户
发布于 2022-06-15 21:58:35
Groupby两列,然后使用nunique
>>> df.groupby(['First Name', 'Last Name']).nunique()页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72638270
复制相关文章
相似问题
腾讯云开发者
