
如何使用python或JavaScript提取文本并将其保存为excel文件
如何使用python或JavaScript提取文本并将其保存为excel文件
提问于 2022-06-16 05:42:35
如何从此PDF文件中提取文本,其中一些数据以表的形式存在,而有些数据则是基于键值的数据。
这就是我尝试过的:
import PyPDF2
import openpyxl
from openpyxl import Workbook
pdfFileObj = open('sample.pdf', 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
pdfReader.numPages
pageObj = pdfReader.getPage(0)
mytext = pageObj.extractText()
wb = Workbook()
sheet = wb.active
sheet.title = 'MyPDF'
sheet['A1'] = mytext
wb.save('sample.xlsx')
print('Save')但是,我希望以以下格式存储数据。

回答 1
Stack Overflow用户
回答已采纳
发布于 2022-06-17 17:19:26
此pdf没有定义良好的表格,因此不能使用任何工具提取一种表格格式的整个数据。我们所能做的就是把整个pdf读成文本。并利用regex提取数据,逐行处理每个数据字段。
在您继续之前,请安装python的pdf管道工包。
pip install pdfplumber假设
这里是一些假设,我为您的pdf,并相应地,我写了代码。

第一行将永远包含标题Account History Report.
- Second行将包含的名称
IMAGE All Notes
- Third行将只包含key:value.
- Fourth行形式的数据
Date Created将只包含数据Number of Pages形式的key:value.
- Fifth行将只包含数据
Client Code, Client Name
- Starting行6,一个pdf可以有多个数据实体,这些数据实体在此pdf中为2,但可以是任意数量的实体。数据实体中的每个数据实体将包含以下fields:
- First行,将只包含数据
Our Ref, Name, Ref 1, Ref 2
- Second行中的数据,数据实体中的
Amount, Total Paid, Balance, Date of A/C, Date Received
- Third行将只包含形式中的数据,数据实体中的
Amount, Total Paid, Balance, Date of A/C, Date Received
- Third行将包含数据
Last Paid, Amt Last Paid, Status, Collector.
- Fourth行,列名为
Date Notes
- The,随后的行将以表的形式包含数据,直到下一个数据实体启动为止。还假定每个数据实体将包含带有键
Our Ref :.
- I的第一个数据,假设数据实体将在每个实体的第一行上分离为
Our Ref :Value Name: Value Ref 1 :Value Ref 2:value
。
pattern = r'Our Ref.*?Name.*?Ref 1.*?Ref 2.*?'- 请注意,我在上面的图像中创建的矩形(厚黑色),我称之为数据实体。
。
- 最终数据将存储在字典(Json)中,根据您在pdf.
中拥有的实体数量,数据实体将具有dataentity1、dataentity2、dataentity3的密钥。
- 头的详细信息作为key:
- 存储在json中,并且我假设每个键只出现在头中一次。
代码
下面是简单而优雅的代码,它以json的形式从pdf中提供信息。在输出中,前几个字段包含来自报头部分的信息,随后的数据实体可以作为data_entity 1和2找到。
在下面的代码中,您只需要更改pdf_path。
import pdfplumber
import re
# regex pattern for keys in line1 of data entity
my_regex_dict_line1 = {
'Our Ref' : r'Our Ref :(.*?)Name',
'Name' : r'Name:(.*?)Ref 1',
'Ref 1' : r'Ref 1 :(.*?)Ref 2',
'Ref 2' : r'Ref 2:(.*?)$'
}
# regex pattern for keys in line2 of data entity
my_regex_dict_line2 = {
'Amount' : r'Amount:(.*?)Total Paid',
'Total Paid' : r'Total Paid:(.*?)Balance',
'Balance' : r'Balance:(.*?)Date of A/C',
'Date of A/C' : r'Date of A/C:(.*?)Date Received',
'Date Received' : r'Date Received:(.*?)$'
}
# regex pattern for keys in line3 of data entity
my_regex_dict_line3 ={
'Last Paid' : r'Last Paid:(.*?)Amt Last Paid',
'Amt Last Paid' : r'Amt Last Paid:(.*?)A/C\s+Status',
'A/C Status': r'A/C\s+Status:(.*?)Collector',
'Collector' : r'Collector :(.*?)$'
}
def preprocess_data(data):
return [el.strip() for el in data.splitlines() if el.strip()]
def get_header_data(text, json_data = {}):
header_data_list = preprocess_data(text)
# third line in text of header contains Date Created field
json_data['Date Created'] = re.search(r'Date Created:(.*?)$', header_data_list[2]).group(1).strip()
# fourth line in text contains Number of Pages, Client Code, Client Name
json_data['Number of Pages'] = re.search(r'Number of Pages:(.*?)$', header_data_list[3]).group(1).strip()
# fifth line in text contains Client Code and ClientName
json_data['Client Code'] = re.search(r'Client Code - (.*?)Client Name', header_data_list[4]).group(1).strip()
json_data['ClientName'] = re.search(r'Client Name - (.*?)$', header_data_list[4]).group(1).strip()
def iterate_through_regex_and_populate_dictionaries(data_dict, regex_dict, text):
''' For the given pattern of regex_dict, this function iterates through each regex pattern and adds the key value to regex_dict dictionary '''
for key, regex in regex_dict.items():
matched_value = re.search(regex, text)
if matched_value is not None:
data_dict[key] = matched_value.group(1).strip()
def populate_date_notes(data_dict, text):
''' This function populates date and Notes in the data chunk in the form of list to data_dict dictionary '''
data_dict['Date'] = []
data_dict['Notes'] = []
iter = 4
while(iter < len(text)):
date_match = re.search(r'(\d{2}/\d{2}/\d{4})',text[iter])
data_dict['Date'].append(date_match.group(1).strip())
notes_match = re.search(r'\d{2}/\d{2}/\d{4}\s*(.*?)$',text[iter])
data_dict['Notes'].append(notes_match.group(1).strip())
iter += 1
data_index = 1
json_data = {}
pdf_path = r'C:\Users\hpoddar\Desktop\Temp\sample3.pdf' # ENTER YOUR PDF PATH HERE
pdf_text = ''
data_entity_sep_pattern = r'(?=Our Ref.*?Name.*?Ref 1.*?Ref 2)'
if(__name__ == '__main__'):
with pdfplumber.open(pdf_path) as pdf:
index = 0
while(index < len(pdf.pages)):
page = pdf.pages[index]
pdf_text += '\n' + page.extract_text()
index += 1
split_on_data_entity = re.split(data_entity_sep_pattern, pdf_text.strip())
# first data in the split_on_data_entity list will contain the header information
get_header_data(split_on_data_entity[0], json_data)
while(data_index < len(split_on_data_entity)):
data_entity = {}
data_processed = preprocess_data(split_on_data_entity[data_index])
iterate_through_regex_and_populate_dictionaries(data_entity, my_regex_dict_line1, data_processed[0])
iterate_through_regex_and_populate_dictionaries(data_entity, my_regex_dict_line2, data_processed[1])
iterate_through_regex_and_populate_dictionaries(data_entity, my_regex_dict_line3, data_processed[2])
if(len(data_processed) > 3 and data_processed[3] != None and 'Date' in data_processed[3] and 'Notes' in data_processed[3]):
populate_date_notes(data_entity, data_processed)
json_data['data_entity' + str(data_index)] = data_entity
data_index += 1
print(json_data)输出:

结果字符串:
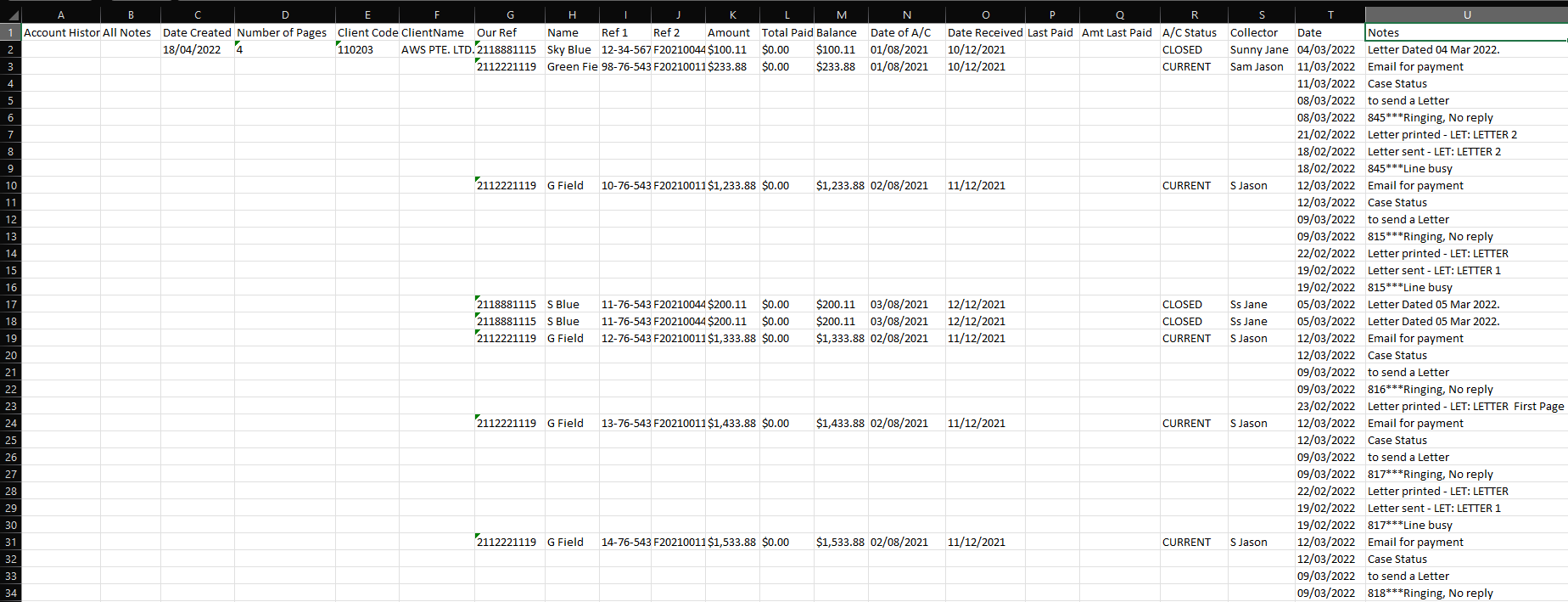
{'Date Created': '18/04/2022', 'Number of Pages': '4', 'Client Code': '110203', 'ClientName': 'AWS PTE. LTD.', 'data_entity1': {'Our Ref': '2118881115', 'Name': 'Sky Blue', 'Ref 1': '12-34-56789-2021/2', 'Ref 2': 'F2021004444', 'Amount': '$100.11', 'Total Paid': '$0.00', 'Balance': '$100.11', 'Date of A/C': '01/08/2021', 'Date Received': '10/12/2021', 'Last Paid': '', 'Amt Last Paid': '', 'A/C Status': 'CLOSED', 'Collector': 'Sunny Jane', 'Date': ['04/03/2022'], 'Notes': ['Letter Dated 04 Mar 2022.']}, 'data_entity2': {'Our Ref': '2112221119', 'Name': 'Green Field', 'Ref 1': '98-76-54321-2021/1', 'Ref 2': 'F2021001111', 'Amount': '$233.88', 'Total Paid': '$0.00', 'Balance': '$233.88', 'Date of A/C': '01/08/2021', 'Date Received': '10/12/2021', 'Last Paid': '', 'Amt Last Paid': '', 'A/C Status': 'CURRENT', 'Collector': 'Sam Jason', 'Date': ['11/03/2022', '11/03/2022', '08/03/2022', '08/03/2022', '21/02/2022', '18/02/2022', '18/02/2022'], 'Notes': ['Email for payment', 'Case Status', 'to send a Letter', '845***Ringing, No reply', 'Letter printed - LET: LETTER 2', 'Letter sent - LET: LETTER 2', '845***Line busy']}}现在,一旦获得json格式的数据,就可以将其加载到csv文件中,作为数据框架或任何需要数据的格式。
保存为xlsx
要在xlsx文件中保存相同的格式,如上面问题中的图像所示。我们可以使用xlsx编写器进行同样的操作。请使用pip安装软件包。
pip install xlsxwriter从前面的代码中,我们将整个数据放在变量json_data中,我们将遍历所有数据实体,并将数据写入代码中由row, col指定的适当单元格。
import xlsxwriter
workbook = xlsxwriter.Workbook('Sample.xlsx')
worksheet = workbook.add_worksheet("Sheet 1")
row = 0
col = 0
# write columns
columns = ['Account History Report', 'All Notes'] + [ key for key in json_data.keys() if 'data_entity' not in key ] + list(json_data['data_entity1'].keys())
worksheet.write_row(row, col, tuple(columns))
row += 1
column_index_map = {}
for index, col in enumerate(columns):
column_index_map[col] = index
# write the header
worksheet.write(row, column_index_map['Date Created'], json_data['Date Created'])
worksheet.write(row, column_index_map['Number of Pages'], json_data['Number of Pages'])
worksheet.write(row, column_index_map['Client Code'], json_data['Client Code'])
worksheet.write(row, column_index_map['ClientName'], json_data['ClientName'])
data_entity_index = 1
#iterate through each data entity and for each key insert the values in the sheet
while True:
data_entity_key = 'data_entity' + str(data_entity_index)
row_size = 1
if(json_data.get(data_entity_key) != None):
for key, value in json_data.get(data_entity_key).items():
if(type(value) == list):
worksheet.write_column(row, column_index_map[key], tuple(value))
row_size = len(value)
else:
worksheet.write(row, column_index_map[key], value)
else:
break
data_entity_index += 1
row += row_size
workbook.close()结果:上面的代码在工作目录中创建一个文件sample.xlsx。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72641009
复制相关文章
相似问题
腾讯云开发者
