
使用熊猫来存储dict格式的值%
使用熊猫来存储dict格式的值%
提问于 2022-06-17 02:28:14
我有如下所示的数据
name,id,AL
A,1,22
A,2,22
B,5,21
B,5,23
B,4,24
C,6,21我想做以下几件事
( a)群name
( b)获取每个id和PL的唯一计数(n唯一性)
在这个post的帮助下,我成功地完成了以下工作
cols = ['id','PL']
for col in cols:
d = {i: x.value_counts(normalize=True).to_dict() for i, x in cf.groupby('name')[col]}
print(pd.Series(d))但是上面的内容并不适用于多列(纯粹是由于我的限制)。
不管怎么说,是否有办法使它适用于多列?我的实际数据有500万行,我在dict (大约5-6列)下有%格式的存储计数值。所以,任何优雅高效的解决方案都欢迎
我希望我的输出如下所示
name id_list AL_list
A {1:0.5,2:0.5} {22:1}
B {5:0.66,4:0.33} {21:0.33,23:0.33,24:0.33}
C {6:1.0} {21:1}更新-基于应答尝试的不正确输出
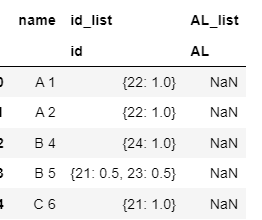
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-06-17 02:36:12
您可以使用groupby进行value_counts,然后转换为dict
out = pd.concat([df.groupby('name')[x].value_counts(normalize=True).round(2).reset_index(level=0).groupby('name').agg(dict) for x in ['id','AL']],axis=1).add_suffix('_list').reset_index()
Out[716]:
name id_list AL_list
0 A {1: 0.5, 2: 0.5} {22: 1.0}
1 B {5: 0.67, 4: 0.33} {21: 0.33, 23: 0.33, 24: 0.33}
2 C {6: 1.0} {21: 1.0}页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72653748
复制相关文章
相似问题
腾讯云开发者
