
如何获得给定关键字的实际Google搜索结果计数?
如何获得给定关键字的实际Google搜索结果计数?
Google是关于搜索结果的统计,它在第一页给出了一个很大的数字(从几十万到几百万),这个数字直到最后一页(通常是20页)才会改变,然后它告诉你它只找到了大约200条结果.
我想知道搜索结果的确切数量,显示在最后一页的数字,搜索查询用双引号括起来,因为我需要精确的参数。
例如,搜索"liberty, equality, fraternity"拥有264,000个结果:
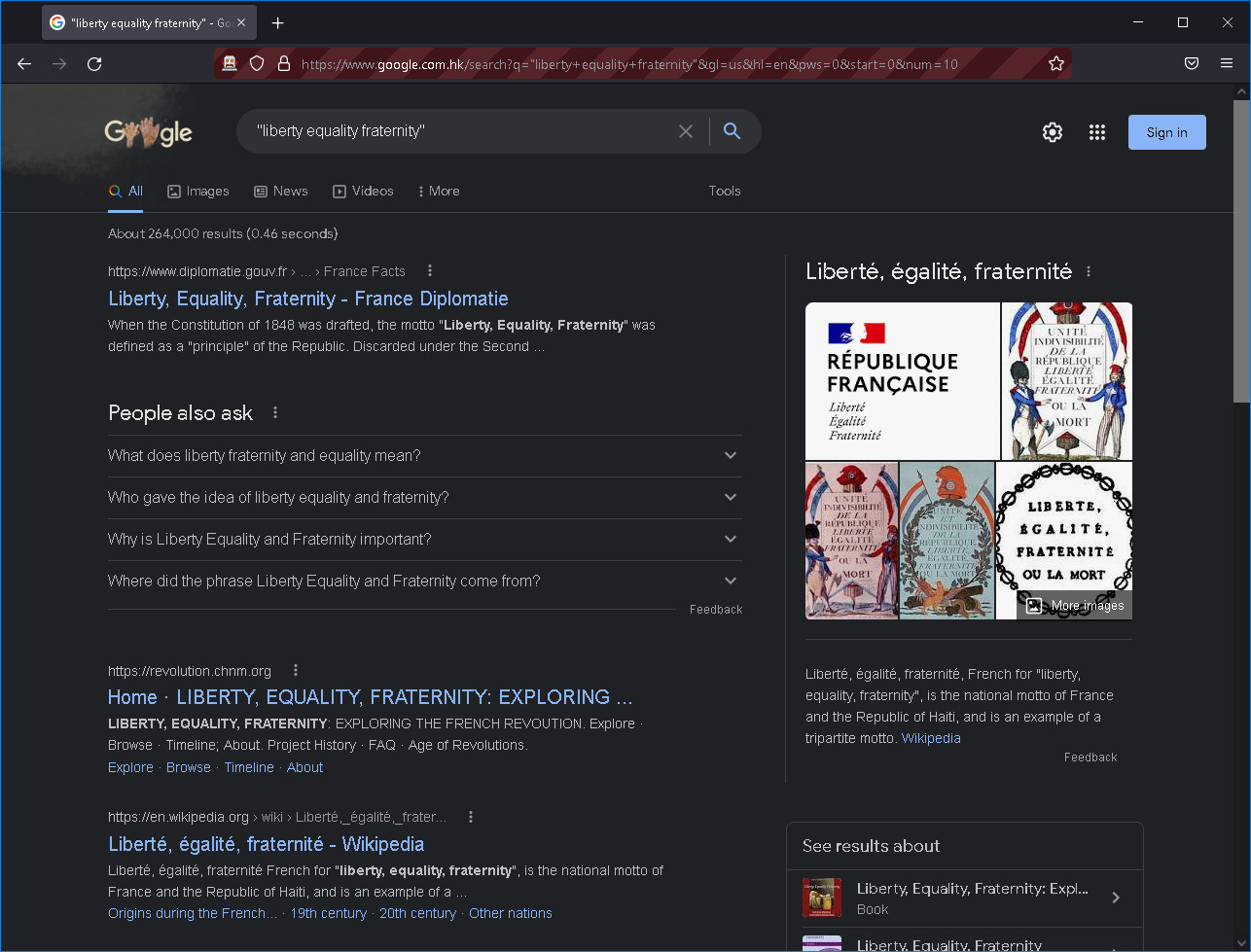
但是它到达了第17页的最后一页,告诉你它只找到了159条结果:
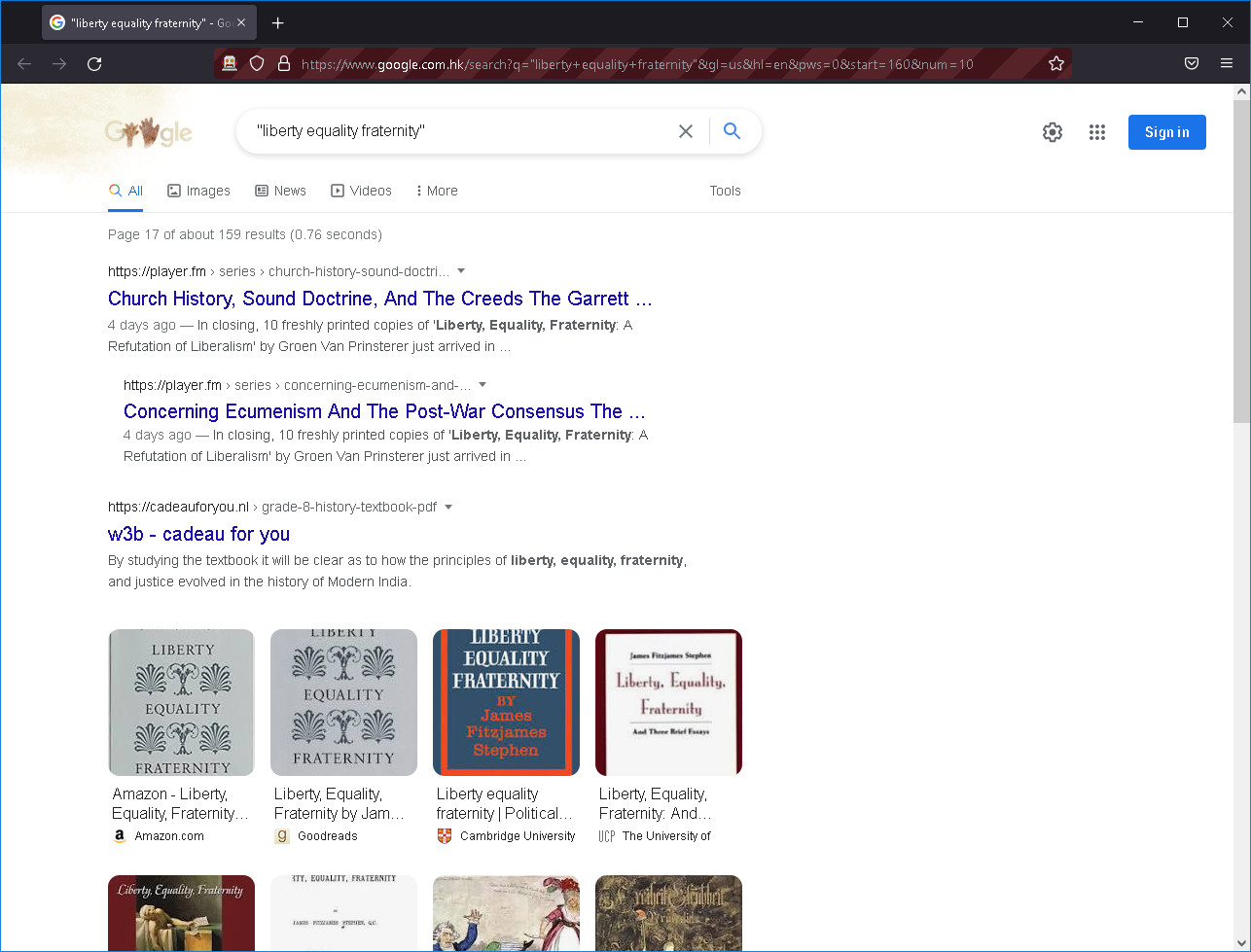
正如您从图像中看到的,我已经编写了一个脚本来完成这个任务,但是它效率极低:
from selenium import webdriver
from string import ascii_letters, digits
Firefox = webdriver.Firefox()
valid = digits + ascii_letters
def url_encode(s):
query = ''
for c in s:
if c in valid:
query += c
elif c == ' ':
query += '+'
else:
query += ''.join(f'%{b:02X}' for b in c.encode('utf8'))
return query
BASE_SEARCH = 'https://www.google.com.hk/search?q=%22{}%22&gl=us&hl=en&pws=0&start={}&num=100'
def search_result_count(s):
query = url_encode(s)
page = 0
Firefox.get(BASE_SEARCH.format(query, page))
count = int(Firefox.find_element(by='id', value='result-stats').text.split()[1].replace(',', ''))
init_count = count
while count == init_count:
page += 1
Firefox.get(BASE_SEARCH.format(query, page*100))
segments = Firefox.find_element(by='id', value='result-stats').text.split()
index = 3
if segments[index] == 'about':
index += 1
count = int(segments[index].replace(',', ''))
return count这样做的目的是在第一页上获得计数,然后使用while循环迭代获得下一页上的计数,直到最后一页的计数才会发生变化,所以将当前计数与第一次计数进行比较,如果它们不相等,则从while循环中分离出来。
但是这种方法非常耗时:
In [3]: %time search_result_count('liberty equality fraternity')
Wall time: 34.3 s
Out[3]: 159我必须解决reCAPTCHA的所有其他用途..。
那么,有什么更好的方法来做到这一点呢?
稍微好一点的方法,但在我的网络仍然缓慢。
这种方法仍然很糟糕,因为我使用VPN,每次运行代码,Google都会通过reCAPTCHA对我说:“我们的系统检测到了来自您网络的异常流量.”,代码会抛出NoSuchElementException,在解决了reCAPTCHA之后,我可以运行完全相同的代码行一次,但在那之后,如果我再次尝试查询,我必须解决另一个reCAPTCHA.
在一个selenium部分中成功查询四到五次之后,任何进一步的查询都将导致403个被禁止的.
我尝试过谷歌自定义搜索JSON,但这不是我想要的,它只能返回10个结果每页,它仍然是关于结果的计数,直到最后一页。
正如谷歌所指出的:
启动整数(uint32格式) 返回的第一个结果的索引。每页的默认结果数为10,因此&start=11将从第二页结果的顶部开始。注意: JSON将永远不会返回超过100个结果,即使超过100个文档与查询匹配,因此将start + num设置为大于100的数字将产生错误。还请注意,num的最大值为10。
Google自定义搜索引擎API将只返回最多100个结果,而且Google获取的结果通常在200左右,因此API在我的用例中是无用的。
我试过这样做:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from string import ascii_letters, digits
options = Options()
options.headless = True
options.page_load_strategy = 'eager'
options.add_argument("--log-level=3")
options.add_argument("--mute-audio")
options.add_argument("--no-sandbox")
options.add_argument("--disable-gpu")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("start-maximized")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
Chrome = webdriver.Chrome(options=options)
Chrome.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
Chrome.execute_cdp_cmd('Network.setUserAgentOverride', {"userAgent": 'Mozilla/5.0 (Android 11; Mobile; rv:68.0) Gecko/68.0 Firefox/101.0', })但我还是被reCAPTCHA拦住了。
我尝试过更多的方法,所有这些方法都是我在谷歌上找到的,它们都没有用。
但是,如果我使用普通浏览器并使用我找到的地址手动搜索这些东西,我就不需要解决reCAPTCHA:
https://www.google.com.hk/search?q=%22{}%22&gl=us&hl=en&pws=0&start={}&num=100&filter=0
但是我需要搜索成千上万的关键词,我其实对Google搜索返回的结果并不感兴趣,只是结果的计数,我试图根据它们的重要性对不同的主题进行排序,而Google返回的结果越多,主题就越重要,就这样简单。
那么,在2022年使用selenium时是否有一种完全避免使用reCAPTCHA的工作方法,或者是否有另一个API提供程序使用Google使用的确切语法,免费返回普通浏览器中的地址指向的内容?
回答 2
Stack Overflow用户
发布于 2022-06-26 14:52:50
您只需查看可用的页面,在WebDriverWait的帮助下,单击它们直到到达最后一个页面。然后用
driver.find_element().text
提取如下结果的数量:
import time
import selenium.webdriver as webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome("/usr/local/bin/chromedriver")
driver.get("https://www.google.com/")
#agree the terms and conditions
WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'L2AGLb'))
).click()
# send query
query = "liberty, equality, fraternity"
search_bar = driver.find_element(By.XPATH, '//input[@class="gLFyf gsfi"]')
search_bar.send_keys(query)
search_bar.send_keys(Keys.ENTER)
# wait to result been loaded
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//h3[@class="LC20lb MBeuO DKV0Md"]'))
)
# loop over page results
while True:
try:
# reach last page
WebDriverWait(driver, 4).until(
EC.element_to_be_clickable((By.XPATH, '//a//span[contains(text(), "Next")]'))
)
# get page available
pages = driver.execute_script("return document.getElementsByClassName('SJajHc NVbCr').length")
goto_page = pages - 1 if pages == 10 else pages - 2
driver.execute_script(f"document.getElementsByClassName('SJajHc NVbCr')[{goto_page}].click();")
time.sleep(1)
except:
print("you reach the last page")
break
#get number of results
result = driver.find_element(By.ID, "result-stats")
print(result.text)
driver.close()这样,就不会有一个reCAPTCHA出来了。好好享受吧。
Stack Overflow用户
发布于 2022-07-14 11:04:26
我已经找了三个小时的答案
假设您有一个带有链接js的html。
- 转到https://console.cloud.google.com/getting-started?supportedpurview=project并创建一个proyect,在凭据部分生成api键,也需要另一个数字。
- 把这个脚本scr放在html /这个脚本需要在HTML中有这个
在js部件函数scrapImageByName(关键字){ $.ajax({ $.ajax:"GET",dataType:"jsonp",url:"https://www.googleapis.com/customsearch/v1",data:{ key:"AIzaSyCzb6SI_JRrp6xLLYV617Ary6n59h36ros",cx:“004286675445984025592:ypgpkv9fjd 4”,过滤器:"1",searchType:“图像”,//imgSize:“小”,q:关键字}}).done(函数(数据){//告警(“成功”);console.log(数据);googleResults = data.items;
$(".result li").remove();
//$('#result').isotope('destroy');
var imageURL = googleResults[0].image.thumbnailLink;
console.log('IMAGE URL', imageURL)
});}
- 这个函数并使用像scrapByName('Banana')这样的参数来调用它。
function scrapImageByName(keyword) {
$.ajax({
type: "GET",
dataType: "jsonp",
url: "https://www.googleapis.com/customsearch/v1",
data: {
key: "AIzaSyCzb6SI_JRrp6xLLYV617Ary6n59h36ros",
cx: "004286675445984025592:ypgpkv9fjd4",
filter: "1",
searchType: "image",
//imgSize: "small",
q: keyword
}
}).done(function (data) {
//alert("Success");
console.log(data);
var googleResults = data.items;
$(".result li").remove();
//$('#result').isotope('destroy');
var imageURL = googleResults[0].image.thumbnailLink;
console.log('IMAGE URL', imageURL)
});
}<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://code.jquery.com/jquery-3.3.1.slim.min.js"></script>
<script src="https://code.jquery.com/jquery-3.3.1.min.js"></script>
</head>
<body>
<p>Open the console and type scrapImageByName('Banana') then you will get imageurl and then you can create a promise and async funcion but this is another thing</p>
</body>
<script>
function scrapImageByName(keyword) {
$.ajax({
type: "GET",
dataType: "jsonp",
url: "https://www.googleapis.com/customsearch/v1",
data: {
key: "AIzaSyCzb6SI_JRrp6xLLYV617Ary6n59h36ros",
cx: "004286675445984025592:ypgpkv9fjd4",
filter: "1",
searchType: "image",
//imgSize: "small",
q: keyword
}
}).done(function (data) {
//alert("Success");
console.log(data);
var googleResults = data.items;
$(".result li").remove();
//$('#result').isotope('destroy');
var imageURL = googleResults[0].image.thumbnailLink;
console.log('IMAGE URL', imageURL)
});
}
</script>
</html>l
https://stackoverflow.com/questions/72676200
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号