
如何根据列值的某些首选项从DataFrame中选择行?
如何根据列值的某些首选项从DataFrame中选择行?
提问于 2022-06-19 18:31:58
我试图通过从现有Df中选择行来创建一个新的DataFrame。
df:
ID val1 val2 uniq
A 10 0 1-2
A 10 0 3-2
B 10 0 8-0
B 9 1 7-6
B 8 2 9-3
c 9 1 10-3
c 9 1 3-0根据val1 &val2上的首选项,每个ID只需要2行:
1) val1 == 10 & val2 == 0 (first preference)
2) val1 == 9 & val2 == 1 (second preference)
3) val1 == 8 & val2 == 2 (third preference)所需产出:
ID val1 val2 uniq
A 10 0 1-2
A 10 0 3-2
B 10 0 8-0
B 9 1 7-6
c 9 1 10-3
c 9 1 3-0在熊猫身上有什么有效的方法吗?耽误您时间,实在对不起!
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-06-19 18:56:40
df.sort_values(['val1', 'val2'], ascending=[False, True]).groupby('ID').head(2)
ID val1 val2 uniq
0 A 10 0 1-2
1 A 10 0 3-2
2 B 10 0 8-0
3 B 9 1 7-6
5 c 9 1 10-3
6 c 9 1 3-0编辑:
如果可能有其他类型的组合,但仅考虑到上述三种组合,则应这样做:
a = (df[['val1', 'val2']].astype(str)
.apply(' '.join, axis = 1).astype('category'))
order = ['10 0', '9 1', '8 2']
levels = np.r_[order, a.cat.remove_categories(order).cat.categories]
df['a'] = a.cat.reorder_categories(levels).cat.as_ordered()
df.sort_values('a').groupby('ID').head(2).drop(columns='a')
ID val1 val2 uniq
0 A 10 0 1-2
1 A 10 0 3-2
2 B 10 0 8-0
3 B 9 1 7-6
5 c 9 1 10-3
6 c 9 1 3-0Stack Overflow用户
发布于 2022-06-19 19:04:47
根据你的喜好,我做了这个
df = {'ID':['A', 'A', 'B', 'B', 'B', 'C', 'C'],
'val1': [10,10,10,9,8,9,9],
'val2': [0,0,0,1,2,1,1]}
df = pd.DataFrame(df)
df1 = df[(df['val1'] == 10) & (df['val2'] == 0)][:2]
df2 = df[(df['val1'] == 9) & (df['val2'] == 1)][:2]
df3 = df[(df['val1'] == 8) & (df['val2'] == 2)][:2]
df4 = df1.append(df2)
df = df4.append(df3)
df.sort_values(['ID'])输出
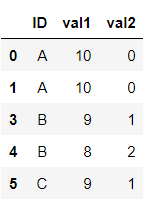
无偏好
df.groupby(['ID']).head(2)输出
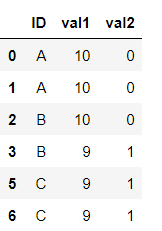
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72679393
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号