
用群函数绘制条形图,并巧妙地绘制流光图
用群函数绘制条形图,并巧妙地绘制流光图
提问于 2022-06-23 19:32:50
我试图绘制一个基于groupby函数的条形图,但是一旦我尝试它,就会崩溃并显示以下错误:
当用户从multiselect小部件中选择3项时,下面会出现此错误。
ValueError:所有参数都应该具有相同的长度。参数
color的长度为3,而先前处理过的参数“性别”、“计数”的长度为95。
代码:
some_columns_df = df.loc[:,['gender','country','city','hoby','company','status']]
some_collumns = some_columns_df.columns.tolist()
select_box_var= st.selectbox("Choose X Column",some_collumns)
multiselect_var= st.multiselect("Select Columns To GroupBy",some_collumns)
test_g3 = df.groupby([select_box_var] + multiselect_var).size().reset_index(name='count')
fig = px.histogram(test_g3,x=select_box_var, y='count',color=multiselect_var ,barmode = 'group',text_auto = True)我知道错误在color px.histogram中的参数中。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-06-23 22:46:08
原因是颜色只接受一个类别。
color=['column_a','column_b']会导致
ValueError:所有参数都应该具有相同的长度。参数
color的长度为2,而先前处理过的参数'total_bill‘的长度为244。
2是list ['column_a','column_b']的长度,244是dataframe的行。
根据文档
(str或int或Series或类似数组)-- data_frame中列的名称,或者熊猫系列或array_like对象的名称。此列或array_like中的值用于为标记指定颜色。
因此,我们要么使用column_name,要么使用series。我的方法是:
import plotly.express as px
df = px.data.tips() # a data set from plotly
df.head()输出
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
栏:
具有唯一值的sex ( Female和Male )
具有唯一值的time -- Dinner和Lunch --我选择了这两列,比较容易理解只有4种组合。
我们创建一个series,它将sex和time列连接起来
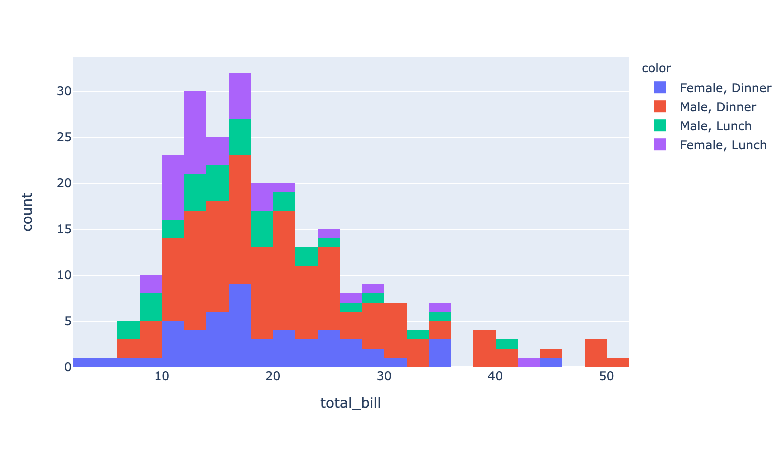
categories = df[['sex','time']].agg(', '.join, axis=1)
print(categories)输出
0 Female, Dinner
1 Male, Dinner
2 Male, Dinner
3 Male, Dinner
4 Female, Dinner
...
239 Male, Dinner
240 Female, Dinner
241 Male, Dinner
242 Male, Dinner
243 Female, Dinner
Length: 244, dtype: object使用此categories作为颜色参考
fig = px.histogram(df, x="total_bill", color =categories)
fig.show()
如果','.join不工作,有问题,
categories = df[['sex','time']].agg(', '.join, axis=1)然后我们尝试另一种方法
categories = df['sex'] + df['time']Sup1

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72735687
复制相关文章
相似问题
腾讯云开发者
