
对数据集应用k均值聚类后,如何对聚类进行标注?
对数据集应用k均值聚类后,如何对聚类进行标注?
提问于 2022-07-15 21:49:45
我有一个.csv格式的数据集,它看起来像-数据
x,y,z, label
2,1,3, A
5,3,1, B
6,2,2, C
9,5,3, B
2,3,4, A
4,1,4, A我想将k均值聚类应用于上述数据集.正如我们在上面看到的,三维数据集(X)。在那之后,我想用图表中的一个特定的集群标签来可视化三维的集群。如果需要更多细节,请告知。
我已经使用了二维数据集,见下文-
kmeans_labels = cluster.KMeans(n_clusters=5).fit_predict(data)绘制二维数据集的可视化图,
plt.scatter(standard_embedding[:, 0], standard_embedding[:, 1], c=kmeans_labels, s=0.1, cmap='Spectral');同样,我想用标签绘制三维聚类图.如果你需要更多的细节,请告诉我。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-07-16 16:43:39
像这样的事情会是一个好的解决方案吗?
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
data = np.array([[2,1,3], [5,3,1], [6,2,2], [9,5,3], [2,3,4], [4,1,4]])
cluster_count = 3
km = KMeans(cluster_count)
clusters = km.fit_predict(data)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(data[:, 0], data[:, 1], data[:, 2], c=clusters, alpha=1)
labels = ["A", "B", "C"]
for i, label in enumerate(labels):
ax.text(km.cluster_centers_[i, 0], km.cluster_centers_[i, 1], km.cluster_centers_[i, 2], label)
ax.set_title("3D K-Means Clustering")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("z")
plt.show()
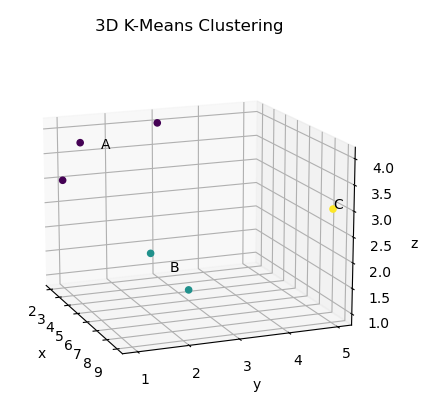
编辑
如果你想要一个传奇,只需这样做:
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
data = np.array([[2,1,3], [5,3,1], [6,2,2], [9,5,3], [2,3,4], [4,1,4]])
cluster_count = 3
km = KMeans(cluster_count)
clusters = km.fit_predict(data)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(data[:, 0], data[:, 1], data[:, 2], c=clusters, alpha=1)
handles = scatter.legend_elements()[0]
ax.legend(title="Clusters", handles=handles, labels = ["A", "B", "C"])
ax.set_title("3D K-Means Clustering")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("z")
plt.show()

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72999895
复制相关文章
相似问题
腾讯云开发者
