
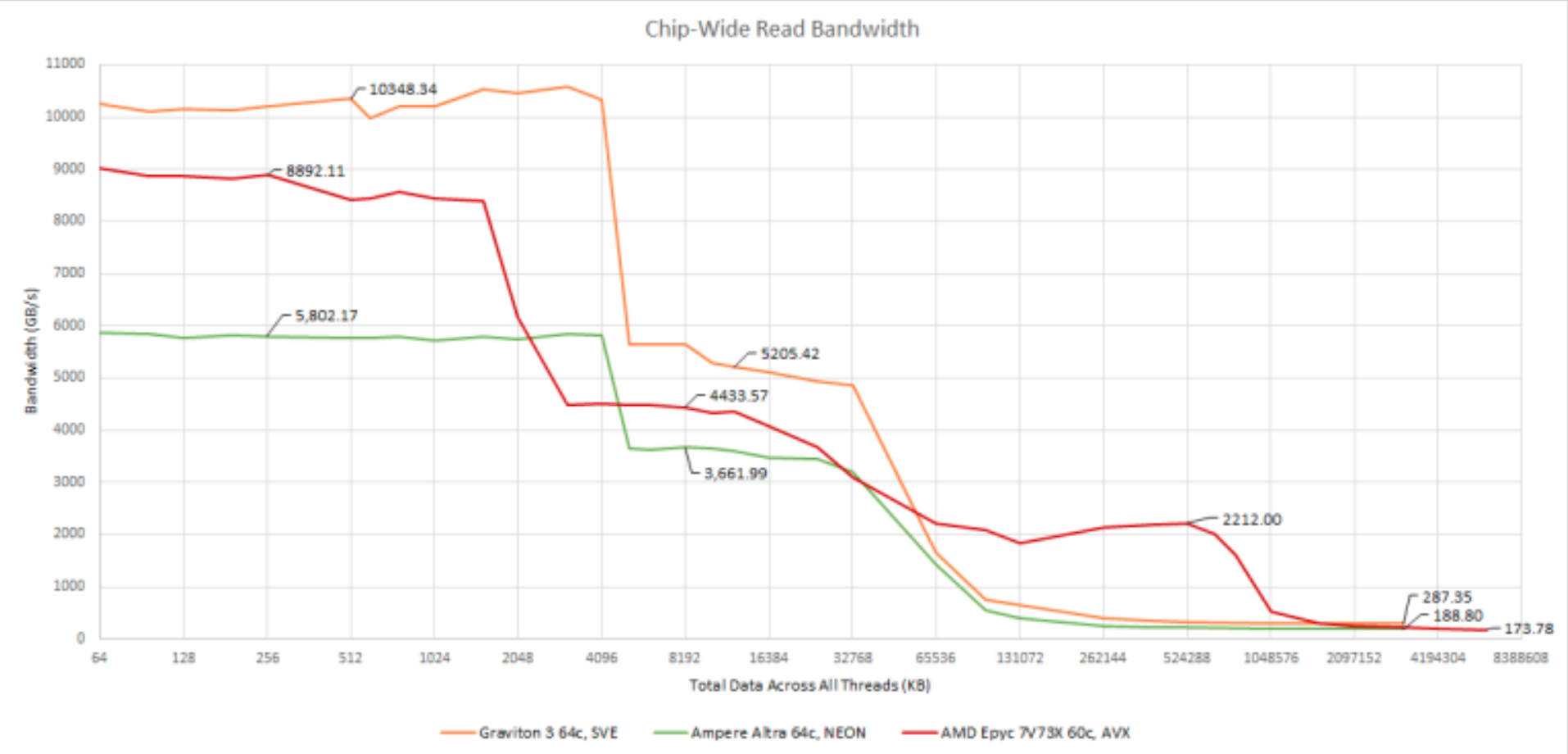
所有L2/L3缓存能被数据使用吗?如果是这样的话,为什么Graviton 3带宽图在L2/L3的一半大小之后会下降,但只是逐渐下降?
回答 3
Stack Overflow用户
发布于 2022-07-19 01:39:59
从情节上看,他们可能没有测试过32米到64米之间的任何尺寸。在所有三个CPU上,这些点之间似乎是一条直线。
由于64M是L2和L3的总尺寸,所以我预计这样的测试会减缓到64M的速度。正如Brendan所说,页面表和一些代码将占用空间,与实际的预期测试数据竞争。如果基准循环很紧,除了中断处理之外,堆栈将不起作用。
一旦你从一个比缓存稍大的工作集合中驱逐任何东西,你通常会在返回之前驱逐几乎所有的东西,这取决于伪LRU的运气。我预计测试大小( 48甚至56 MiB )比64 MiB数据点更接近32 MiB数据点。
Stack Overflow用户
发布于 2022-07-19 01:11:12
所有L2/L3缓存能被数据使用吗?
理论上,是的;但只有在缓存中没有“非数据”(代码)的情况下,只有在计算“所有数据”(而不只是计算进程的数据而忽略堆栈和页表)的情况下,并且只有在没有任何别名问题的情况下。
但是为什么下一个悬崖从32 at开始呢?为什么下降的速度如此缓慢?
对于一个完全关联的缓存,我预计会突然下降到/接近32 MiB。然而,大型缓存几乎从来都不是完全关联的,因为在缓存中找到任何东西需要花费很多时间。
随着相联性的降低,冲突发生的几率也随之增加。例如,对于一个8路关联的64 MiB缓存,病态的情况是,所有的东西都会发生冲突,而您只能有效地使用其中的8 MiB。
更具体地说,对于64 MiB缓存(具有未知的关联性),以及缺乏对缓存着色的支持的“假定的Linux”环境,有理由期待以64 MiB为结束的平稳下降。
Stack Overflow用户
发布于 2022-10-12 18:51:57
澄清一下,在AWS中运行的Graviton 3上,lscpu为L3提供了32MiB,而不是64 MiB。
缓存(总数之和):L1d: 4个MiB (64个实例) L1i: 4个MiB (64个实例) L2: 64个MiB (64个实例) L3: 32个MiB (1个实例)
最初的问题是假设所有核的L3为64 MiB。
但是为什么下一个悬崖从32 at开始呢?为什么下降的速度如此缓慢?64核的私有L2缓存共有64 MiB,与共享L3大小相同。区块报价
https://stackoverflow.com/questions/73029907
复制相似问题
腾讯云开发者
