
IMPORTXML返回#NA (未找到url上的资源)和#NA [导入的内容为空]
我一直在开发一个使用IMPORTXML从同一工作表N列中的不同URL中提取多个数据的google工作表。大多数数据都是在所需的单元格中正确导入的,但是一些单元正在返回#NA资源,在url未找到,还有一些单元格正在返回#NA,导入的内容是空的,,我已经尽力了,但没有结果。
这是在url未找到处返回#NA资源的公式之一。它应该从kategoria从https://www.tim.pl/gniazdo-do-przekaznikow-serii-60-13-88-02-modulow-czasowych-86-90-03smaa进口。
=IMPORTXML(N13;“//ul@class=‘breadcrumbs_list主题--light’/li5//a//span”)
这是返回#NA导入内容为空的公式之一。它应该从kategoria从https://www.tim.pl/wyszukiwanie/wyniki/?q=60.13.8.230.0040&p=1&category=ALL&query=60.13.8.230.0040&dir=desc&order=p3m&limit=24进口。
=IMPORTXML(N12;“//ul@class=‘breadcrumbs_list主题--light’/li5//a//span”)
这是到工作表HDljCRm8bFX4tsRc/编辑?usp=共享的链接
我很感激我能得到的一切帮助。
Stack Overflow用户
发布于 2022-07-19 02:15:08
我相信你的目标如下。
- 您希望使用IMPORTXML从
kategoria的URL中检索https://www.tim.pl/###的值。
当我看到https://www.tim.pl/gniazdo-do-przekaznikow-serii-60-13-88-02-modulow-czasowych-86-90-03smaa的URL时,似乎没有看到kategoria的值,因为它的状态代码是"404“。这样,#N/A就返回了。
似乎在div的URL中没有带有breadcrumbs__list theme--light类的https://www.tim.pl/wyszukiwanie/wyniki/?q=60.13.8.230.0040&p=1&category=ALL&query=60.13.8.230.0040&dir=desc&order=p3m&limit=24。这样,#N/A就返回了。
我认为在这种情况下,可能需要为您的URL使用通用的XPath来检索您的期望值。对于这一点,下面的示例公式如何?
样本公式:
=IFERROR(IMPORTXML(B1;"//div[@data-categories-trail or contains(@class,'layout product-box')][1]//div[./span[text()='Kategoria:']]/a"))- 在本例中,URL放在单元格"B1“中。
测试:
当为提供的电子表格中提供的URL使用此示例公式时,将获得以下结果。
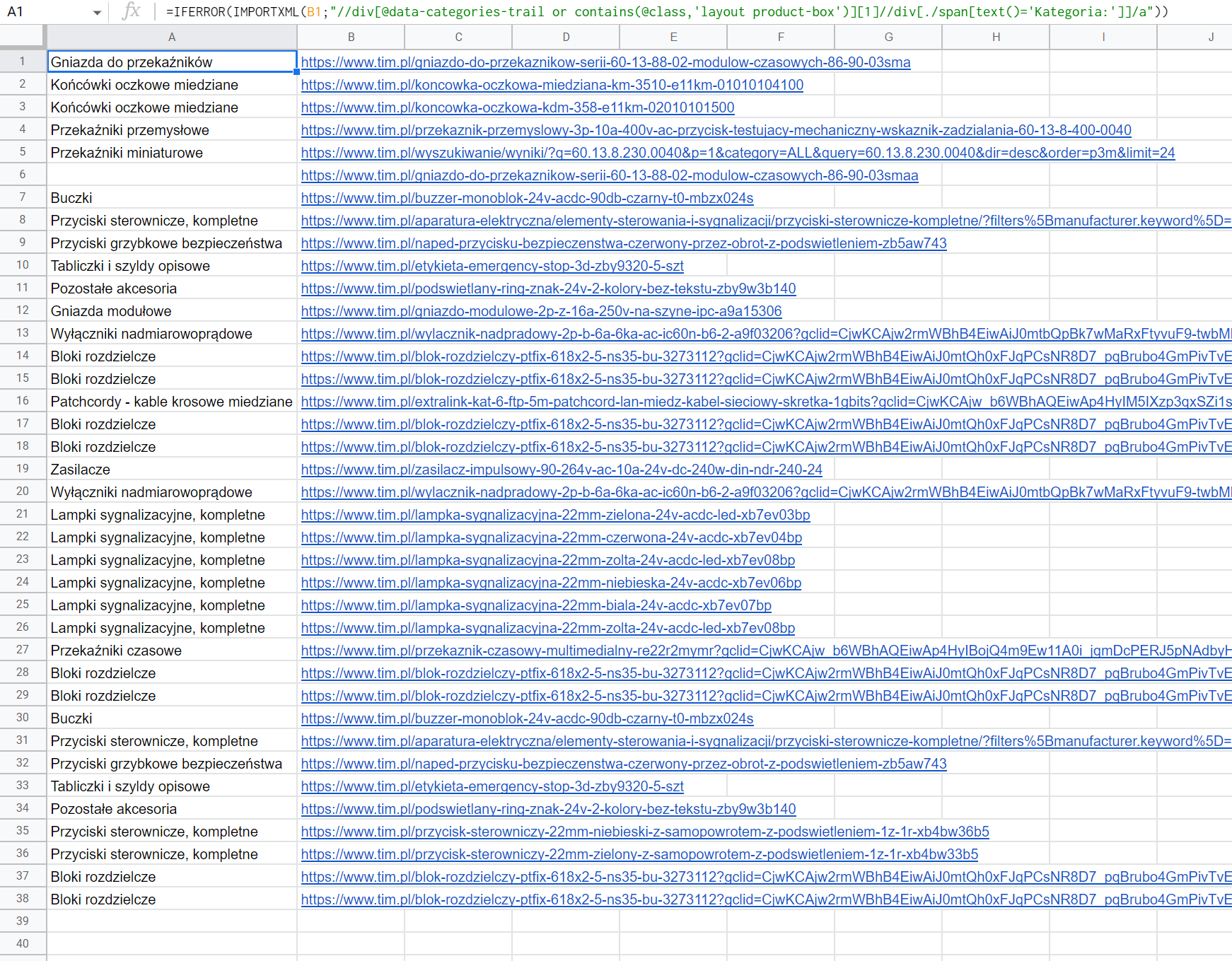
- 在这种情况下,如果找不到
kategoria的值,则返回空值。
注意:
- 在此示例公式中,将使用您提供的URL。因此,当您使用其他URL时,可能无法使用此示例公式。请小心这件事。
- 从
It is supposed to import kategoria from URL的问题中,这个示例公式检索kategoria的值。因此,当您想检索其他值时,请将其作为一个新问题发布。
参考资料:
https://stackoverflow.com/questions/73029937
复制相似问题
腾讯云开发者
