
fun.min、fun.max和stat_summary是如何工作的?
对不起,我知道这个问题实际上已经被问到here了,但是我仍然不明白这些摘要函数( fun.min、fun.max、fun)是如何真正工作的。在手册示例中,这些函数通常在以下上下文中定义为
ggplot(data = <DATA>) +
stat_summary(
mapping = aes(<MAPPINGS>),
fun.min = min,
fun.max = max,
fun = median
)据我所知,fun.min = min将摘要函数定义为min基R函数,但是会发生什么呢?fun.min如何知道如何找到映射参数的最小值?退一步,为什么fun.min必须被定义为min基R函数,因为它不是已经定义为在向量中找到最小值,然后返回一个数字吗?
Stack Overflow用户
发布于 2022-07-20 07:14:33
让我们从一个简单的例子开始:
library(ggplot2)
base <- ggplot(data = mtcars, mapping = aes(cyl, mpg)) +
geom_point()
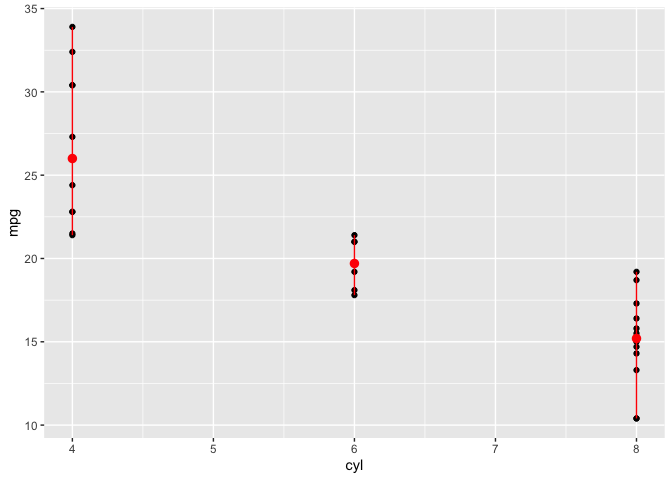
base + stat_summary(
fun.min = min,
fun.max = max,
fun = median,
color = "red"
)
现在请回答你们的问题:
据我所知,
fun.min = min将摘要函数定义为min基R函数,但是会发生什么呢?fun.min如何知道如何找到映射参数的最小值?
在stat_summary下,它聚合通过data参数传递的数据集,即对于x变量的每个值或类别(或者在更一般的情况下,x和group美学之间的交互),它为映射在y aes上的变量计算fun、fun.min和fun.max定义的三个统计数据。然后,fun计算的值映射到y上,fun.min值映射到ymin上,fun.max值映射到ymax上。
这个步骤的结果可以通过ggplot2::layer_data显示。对于基本示例
layer_data(last_plot(), 2) # The 2 means we want the data for the second layer. geom_point = first layer, stat_summary = second layer
#> x group y ymin ymax PANEL flipped_aes colour size linetype shape fill
#> 1 4 -1 26.0 21.4 33.9 1 FALSE red 0.5 1 19 NA
#> 2 6 -1 19.7 17.8 21.4 1 FALSE red 0.5 1 19 NA
#> 3 8 -1 15.2 10.4 19.2 1 FALSE red 0.5 1 19 NA
#> alpha stroke
#> 1 NA 1
#> 2 NA 1
#> 3 NA 1此外,ggplot2还添加了许多其他内容,基本上与
library(dplyr, warn = FALSE)
mtcars |>
group_by(x = cyl) |>
summarise(y = median(mpg), ymin = min(mpg), ymax = max(mpg))
#> # A tibble: 3 × 4
#> x y ymin ymax
#> <dbl> <dbl> <dbl> <dbl>
#> 1 4 26 21.4 33.9
#> 2 6 19.7 17.8 21.4
#> 3 8 15.2 10.4 19.2后退一步,为什么
fun.min必须被定义为min基R函数,因为它不是已经定义为在向量中找到最小值,然后返回一个数字吗?
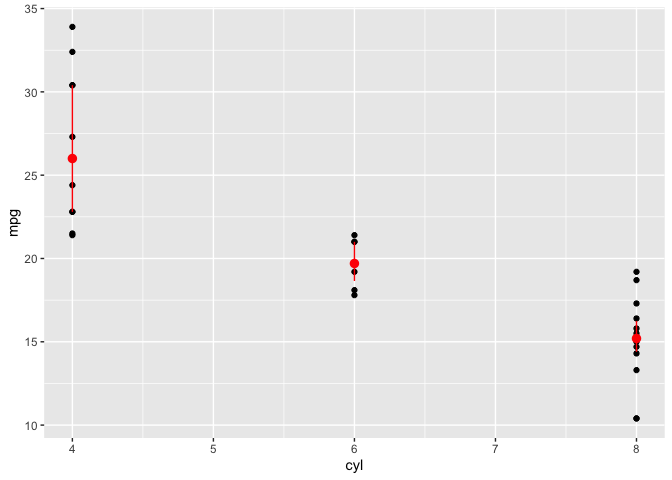
答案是否定的。fun.min不被定义为最小值或min函数。默认情况下,它是NULL (参见?stat_summary)。fun.min提供了用于计算要映射到ymin aes上的汇总统计数据的函数。如果将fun.min固定在minimum上,stat_summary就不会那么有用,例如,我们经常使用fun.min和fun.max来显示置信区间或显示四分位数范围:
base + stat_summary(
fun.min = ~quantile(.x, probs = .25),
fun.max = ~quantile(.x, probs = .75),
fun = median,
color = "red"
)
https://stackoverflow.com/questions/73045987
复制相似问题
腾讯云开发者
