
和yfinance问题
和yfinance问题
提问于 2022-07-21 08:52:54
我只列出到目前为止我所知道的两个bug,如果您对重构我的代码有任何建议,请告诉我,我将继续列出到目前为止已知的几个问题。
- yfinance并没有在我的字典中添加
dividendYield,我确实确保了它们是这些符号的实际股息收益。
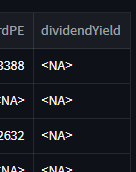
我认为
TypeError: can only concatenate str (not "Tag") to str与它如何通过xml进行解析有关,它遇到了一个标记,所以我无法创建扩展程序,我以为我可以用这个if语句来解决它,但是我根本没有得到任何扩展器。
with st.expander("Expand for stocks news"):
for heading in fin_headings:
if heading == str:
st.markdown("* " + heading)
else:
passMain.py的完整代码:
import requests
import spacy
import pandas as pd
import yfinance as yf
import streamlit as st
from bs4 import BeautifulSoup
st.title("Fire stocks :fire:")
nlp = spacy.load("en_core_web_sm")
def extract_rss(rss_link):
# Parses xml, and extracts the headings.
headings = []
response1 = requests.get(
"http://feeds.marketwatch.com/marketwatch/marketpulse/")
response2 = requests.get(rss_link)
parse1 = BeautifulSoup(response1.content, features="xml")
parse2 = BeautifulSoup(response2.content, features="xml")
headings1 = parse1.findAll('title')
headings2 = parse2.findAll('title')
headings = headings1 + headings2
return headings
def stock_info(headings):
# Get the entities from each heading, link it with nasdaq data // if possible, and Extract market data with yfinance.
stock_dict = {
'Org': [],
'Symbol': [],
'currentPrice': [],
'dayHigh': [],
'dayLow': [],
'forwardPE': [],
'dividendYield': []
}
stocks_df = pd.read_csv("./data/nasdaq_screener_1658383327100.csv")
for title in headings:
doc = nlp(title.text)
for ent in doc.ents:
try:
if stocks_df['Name'].str.contains(ent.text).sum():
symbol = stocks_df[stocks_df['Name'].str.contains(
ent.text)]['Symbol'].values[0]
org_name = stocks_df[stocks_df['Name'].str.contains(
ent.text)]['Name'].values[0]
# Recieve info from yfinance
stock_info = yf.Ticker(symbol).info
print(symbol)
stock_dict['Org'].append(org_name)
stock_dict['Symbol'].append(symbol)
stock_dict['currentPrice'].append(
stock_info['currentPrice'])
stock_dict['dayHigh'].append(stock_info['dayHigh'])
stock_dict['dayLow'].append(stock_info['dayLow'])
stock_dict['forwardPE'].append(stock_info['forwardPE'])
stock_dict['dividendYield'].append(
stock_info['dividendYield'])
else:
# If name can't be found pass.
pass
except:
# Don't raise an error.
pass
output_df = pd.DataFrame.from_dict(stock_dict, orient='index')
output_df = output_df.transpose()
return output_df
# Add input field input field
user_input = st.text_input(
"Add rss link here", "https://www.investing.com/rss/news.rss")
# Get financial headlines
fin_headings = extract_rss(user_input)
print(fin_headings)
# Output financial info
output_df = stock_info(fin_headings)
output_df.drop_duplicates(inplace=True, subset='Symbol')
st.dataframe(output_df)
with st.expander("Expand for stocks news"):
for heading in fin_headings:
if heading == str:
st.markdown("* " + heading)
else:
pass回答 2
Stack Overflow用户
回答已采纳
发布于 2022-07-27 16:37:26
stock_info函数中的逻辑中存在一个问题,因为同一个符号得到不同的值,并且在清理重复时,根据符号的出现情况,它保留了第一次出现符号的行。
下面的代码将解决两个问题。
import requests
import spacy
import pandas as pd
import yfinance as yf
import streamlit as st
from bs4 import BeautifulSoup
st.title("Fire stocks :fire:")
nlp = spacy.load("en_core_web_sm")
def extract_rss(rss_link):
# Parses xml, and extracts the headings.
headings = []
response1 = requests.get(
"http://feeds.marketwatch.com/marketwatch/marketpulse/")
response2 = requests.get(rss_link)
parse1 = BeautifulSoup(response1.content, features="xml")
parse2 = BeautifulSoup(response2.content, features="xml")
headings1 = parse1.findAll('title')
headings2 = parse2.findAll('title')
headings = headings1 + headings2
return headings
def stock_info(headings):
stock_info_list = []
stocks_df = pd.read_csv("./data/nasdaq_screener_1658383327100.csv")
for title in headings:
doc = nlp(title.text)
for ent in doc.ents:
try:
if stocks_df['Name'].str.contains(ent.text).sum():
symbol = stocks_df[stocks_df['Name'].str.contains(
ent.text)]['Symbol'].values[0]
org_name = stocks_df[stocks_df['Name'].str.contains(
ent.text)]['Name'].values[0]
# Recieve info from yfinance
print(symbol)
stock_info = yf.Ticker(symbol).info
stock_info['Org'] = org_name
stock_info['Symbol'] = symbol
stock_info_list.append(stock_info)
else:
# If name can't be found pass.
pass
except:
# Don't raise an error.
pass
output_df = pd.DataFrame(stock_info_list)
return output_df
# Add input field input field
user_input = st.text_input(
"Add rss link here", "https://www.investing.com/rss/news.rss")
# Get financial headlines
fin_headings = extract_rss(user_input)
output_df = stock_info(fin_headings)
output_df = output_df[['Org','Symbol','currentPrice','dayHigh','dayLow','forwardPE','dividendYield']]
output_df.drop_duplicates(inplace=True, subset='Symbol')
st.dataframe(output_df)
with st.expander("Expand for stocks news"):
for heading in fin_headings:
heading = heading.text
if type(heading) == str:
st.markdown("* " + heading)
else:
passStack Overflow用户
发布于 2022-07-23 20:05:58
对于问题#2,您发布的修补程序代码有一个小错误。与其检查heading == str (它所做的事情与您的预期完全不同,而且始终是False ),不如检查isinstance(heading, str)是否。这样,如果True是字符串,则可以得到False,如果不是,则得到False。但是,即使这样,它也不应该是一个解决方案,因为heading不是一个字符串。相反,您需要调用heading上的heading来获取解析对象的实际文本部分。
heading.get_text()需要更多信息来解决#1问题。在创建Dataframe之前,stock_dict是什么样子的?具体来说,stock_dict['dividendYield']中有哪些值?你能把它打印出来并添加到你的问题中吗?
另外,关于重构部分。一个
else:
pass块完全不做任何操作,应该删除。(如果条件为false,任何事情都不会发生)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73063306
复制相关文章
相似问题
腾讯云开发者
