
NoSuchMethodError: org.apache.scapk.sql.kafka010消费者
我使用星火结构化流来读取来自卡夫卡的多个主题的信息。我面临以下错误: org.apache.spark.sql.kafka010.consumer.InternalKafkaConsumerPool$PoolConfig.setMinEvictableIdleTime(Ljava/time/Duration;)V:java.lang.NoSuchMethodError
下面是我使用的maven依赖项,
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>untitled</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>A Camel Scala Route</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencyManagement>
<dependencies>
<!-- Camel BOM -->
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-parent</artifactId>
<version>2.25.4</version>
<scope>import</scope>
<type>pom</type>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-core</artifactId>
</dependency>
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-scala</artifactId>
</dependency>
<!-- scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.13.8</version>
</dependency>
<dependency>
<groupId>org.scala-lang.modules</groupId>
<artifactId>scala-xml_2.13</artifactId>
<version>2.1.0</version>
</dependency>
<!-- logging -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<scope>runtime</scope>
</dependency>
<!--spark-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.3.0</version>
</dependency>
<!--spark Streaming kafka-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.13</artifactId>
<version>3.3.0</version>
</dependency>
<!--kafka-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>3.2.0</version>
</dependency>
<!--jackson-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.3</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.13.3</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.13.3</version>
</dependency>
<!-- testing -->
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<defaultGoal>install</defaultGoal>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<!-- the Maven compiler plugin will compile Java source files -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
<configuration>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- the Maven Scala plugin will compile Scala source files -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- configure the eclipse plugin to generate eclipse project descriptors for a Scala project -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<version>2.10</version>
<configuration>
<projectnatures>
<projectnature>org.scala-ide.sdt.core.scalanature</projectnature>
<projectnature>org.eclipse.jdt.core.javanature</projectnature>
</projectnatures>
<buildcommands>
<buildcommand>org.scala-ide.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<classpathContainers>
<classpathContainer>org.scala-ide.sdt.launching.SCALA_CONTAINER</classpathContainer>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
</classpathContainers>
<excludes>
<exclude>org.scala-lang:scala-library</exclude>
<exclude>org.scala-lang:scala-compiler</exclude>
</excludes>
<sourceIncludes>
<sourceInclude>**/*.scala</sourceInclude>
<sourceInclude>**/*.java</sourceInclude>
</sourceIncludes>
</configuration>
</plugin>
<!-- allows the route to be run via 'mvn exec:java' -->
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.6.0</version>
<configuration>
<mainClass>org.example.MyRouteMain</mainClass>
</configuration>
</plugin>
</plugins>
</build>
</project>Scala版本:2.13.8火花版本:3.3.0
这是我从Kafka主题中读到的代码片段:
object consumerMain {
val log : Logger = Logger.getLogger(controller.driver.getClass)
val config: Map[String, String]=Map[String,String](
"kafka.bootstrap.servers" -> bootstrapServer,
"startingOffsets" -> "earliest",
"kafka.security.protocol" -> security_protocol,
"kafka.ssl.truststore.location" -> truststore_location,
"kafka.ssl.truststore.password" -> password,
"kafka.ssl.keystore.location" -> keystore_location,
"kafka.ssl.keystore.password" -> password,
"kafka.ssl.key.password"-> password,
"kafka.ssl.endpoint.identification.algorithm"-> ""
)
def main(args: Array[String]) : Unit ={
log.info("SPARKSESSION CREATED!!!")
val spark = SparkSession.builder()
.appName("kafka-sample-consumer")
.master("local")
.getOrCreate()
log.info("READING MESSAGES FROM KAFKA!!!")
val kafkaMsg = spark
.readStream
.format("Kafka")
.options(config)
.option("kafka.group.id", group_id)
.option("subscribe", "sample_topic_T")
.load()
kafkaMsg.printSchema()
kafkaMsg.writeStream
.format("console")
//.outputMode("append")
.start()
.awaitTermination()
}
}下面,我可以看到我在控制台上打印的日志中设置的kafka proeprties:
[ main] StateStoreCoordinatorRef INFO Registered StateStoreCoordinator endpoint
[ main] ContextHandler INFO Started o.s.j.s.ServletContextHandler@6e00837f{/StreamingQuery,null,AVAILABLE,@Spark}
[ main] ContextHandler INFO Started o.s.j.s.ServletContextHandler@6a5dd083{/StreamingQuery/json,null,AVAILABLE,@Spark}
[ main] ContextHandler INFO Started o.s.j.s.ServletContextHandler@1e6bd263{/StreamingQuery/statistics,null,AVAILABLE,@Spark}
[ main] ContextHandler INFO Started o.s.j.s.ServletContextHandler@635ff2a5{/StreamingQuery/statistics/json,null,AVAILABLE,@Spark}
[ main] ContextHandler INFO Started o.s.j.s.ServletContextHandler@62735b13{/static/sql,null,AVAILABLE,@Spark}
[ main] ResolveWriteToStream WARN Temporary checkpoint location created which is deleted normally when the query didn't fail: C:\Users\xyz\AppData\Local\Temp\temporary-c2ca1d2c-2c8d-4961-a1bd-1881bc00e0bb. If it's required to delete it under any circumstances, please set spark.sql.streaming.forceDeleteTempCheckpointLocation to true. Important to know deleting temp checkpoint folder is best effort.
[ main] ResolveWriteToStream INFO Checkpoint root C:\Users\xyz\AppData\Local\Temp\temporary-c2ca1d2c-2c8d-4961-a1bd-1881bc00e0bb resolved to file:/C:/Users/xyz/AppData/Local/Temp/temporary-c2ca1d2c-2c8d-4961-a1bd-1881bc00e0bb.
[ main] ResolveWriteToStream WARN spark.sql.adaptive.enabled is not supported in streaming DataFrames/Datasets and will be disabled.
[ main] CheckpointFileManager INFO Writing atomically to file:/C:/Users/xyz/AppData/Local/Temp/temporary-c2ca1d2c-2c8d-4961-a1bd-1881bc00e0bb/metadata using temp file file:/C:/Users/xyz/AppData/Local/Temp/temporary-c2ca1d2c-2c8d-4961-a1bd-1881bc00e0bb/.metadata.c2b5aa2a-2a86-4931-a4f0-bbdaae8c3d5f.tmp
[ main] CheckpointFileManager INFO Renamed temp file file:/C:/Users/xyz/AppData/Local/Temp/temporary-c2ca1d2c-2c8d-4961-a1bd-1881bc00e0bb/.metadata.c2b5aa2a-2a86-4931-a4f0-bbdaae8c3d5f.tmp to file:/C:/Users/xyz/AppData/Local/Temp/temporary-c2ca1d2c-2c8d-4961-a1bd-1881bc00e0bb/metadata
[ main] MicroBatchExecution INFO Starting [id = 54eadb58-a957-4f8d-b67e-24ef6717482c, runId = ceb06ba5-1ce6-4ccd-bfe9-b4e24fd497a6]. Use file:/C:/Users/xyz/AppData/Local/Temp/temporary-c2ca1d2c-2c8d-4961-a1bd-1881bc00e0bb to store the query checkpoint.
[5-1ce6-4ccd-bfe9-b4e24fd497a6]] MicroBatchExecution INFO Reading table [org.apache.spark.sql.kafka010.KafkaSourceProvider$KafkaTable@5efc8880] from DataSourceV2 named 'Kafka' [org.apache.spark.sql.kafka010.KafkaSourceProvider@2703aebd]
[5-1ce6-4ccd-bfe9-b4e24fd497a6]] KafkaSourceProvider WARN Kafka option 'kafka.group.id' has been set on this query, it is
not recommended to set this option. This option is unsafe to use since multiple concurrent
queries or sources using the same group id will interfere with each other as they are part
of the same consumer group. Restarted queries may also suffer interference from the
previous run having the same group id. The user should have only one query per group id,
and/or set the option 'kafka.session.timeout.ms' to be very small so that the Kafka
consumers from the previous query are marked dead by the Kafka group coordinator before the
restarted query starts running.
[5-1ce6-4ccd-bfe9-b4e24fd497a6]] MicroBatchExecution INFO Starting new streaming query.
[5-1ce6-4ccd-bfe9-b4e24fd497a6]] MicroBatchExecution INFO Stream started from {}
[5-1ce6-4ccd-bfe9-b4e24fd497a6]] ConsumerConfig INFO ConsumerConfig values:
auto.commit.interval.ms = 5000
auto.offset.reset = earliest
bootstrap.servers = [localhost:9092, localhost: 9093]
check.crcs = true
client.dns.lookup = default
client.id =
connections.max.idle.ms = 540000
default.api.timeout.ms = 60000
enable.auto.commit = false
exclude.internal.topics = true
fetch.max.bytes = 52428800
fetch.max.wait.ms = 500
fetch.min.bytes = 1
group.id = kafka-message-test-group
heartbeat.interval.ms = 3000
interceptor.classes = []
internal.leave.group.on.close = true
isolation.level = read_uncommitted
key.deserializer = class org.apache.kafka.common.serialization.ByteArrayDeserializer
max.partition.fetch.bytes = 1048576
max.poll.interval.ms = 300000
max.poll.records = 1
metadata.max.age.ms = 300000
metric.reporters = []
metrics.num.samples = 2
metrics.recording.level = INFO
metrics.sample.window.ms = 30000
partition.assignment.strategy = [class org.apache.kafka.clients.consumer.RangeAssignor]
receive.buffer.bytes = 65536
reconnect.backoff.max.ms = 1000
reconnect.backoff.ms = 50
request.timeout.ms = 30000
retry.backoff.ms = 100
sasl.client.callback.handler.class = null
sasl.jaas.config = null
sasl.kerberos.kinit.cmd = /usr/bin/kinit
sasl.kerberos.min.time.before.relogin = 60000
sasl.kerberos.service.name = null
sasl.kerberos.ticket.renew.jitter = 0.05
sasl.kerberos.ticket.renew.window.factor = 0.8
sasl.login.callback.handler.class = null
sasl.login.class = null
sasl.login.refresh.buffer.seconds = 300
sasl.login.refresh.min.period.seconds = 60
sasl.login.refresh.window.factor = 0.8
sasl.login.refresh.window.jitter = 0.05
sasl.mechanism = GSSAPI
security.protocol = SSL
send.buffer.bytes = 131072
session.timeout.ms = 10000
ssl.cipher.suites = null
ssl.enabled.protocols = [TLSv1.2, TLSv1.1, TLSv1]
ssl.endpoint.identification.algorithm =
ssl.key.password = [hidden]
ssl.keymanager.algorithm = SunX509
ssl.keystore.location = src/main/resources/consumer_inlet/keystore.jks
ssl.keystore.password = [hidden]
ssl.keystore.type = JKS
ssl.protocol = TLS
ssl.provider = null
ssl.secure.random.implementation = null
ssl.trustmanager.algorithm = PKIX
ssl.truststore.location = src/main/resources/consumer_inlet/truststore.jks
ssl.truststore.password = [hidden]
ssl.truststore.type = JKS
value.deserializer = class org.apache.kafka.common.serialization.ByteArrayDeserializer运行consumerMain时遇到以下错误:
Exception in thread "main" org.apache.spark.sql.streaming.StreamingQueryException: Writing job aborted
=== Streaming Query ===
Identifier: [id = 54eadb58-a957-4f8d-b67e-24ef6717482c, runId = ceb06ba5-1ce6-4ccd-bfe9-b4e24fd497a6]
Current Committed Offsets: {}
Current Available Offsets: {KafkaV2[Subscribe[sample_topic_T]]: {"clinical_sample_T":{"0":155283144,"1":155233229}}}
Current State: ACTIVE
Thread State: RUNNABLE
Logical Plan:
WriteToMicroBatchDataSource org.apache.spark.sql.execution.streaming.ConsoleTable$@4f9c824, 54eadb58-a957-4f8d-b67e-24ef6717482c, Append
+- StreamingDataSourceV2Relation [key#7, value#8, topic#9, partition#10, offset#11L, timestamp#12, timestampType#13], org.apache.spark.sql.kafka010.KafkaSourceProvider$KafkaScan@135a05da, KafkaV2[Subscribe[sample_topic_T]]
at org.apache.spark.sql.execution.streaming.StreamExecution.org$apache$spark$sql$execution$streaming$StreamExecution$$runStream(StreamExecution.scala:330)
at org.apache.spark.sql.execution.streaming.StreamExecution$$anon$1.run(StreamExecution.scala:208)
Caused by: org.apache.spark.SparkException: Writing job aborted
at org.apache.spark.sql.errors.QueryExecutionErrors$.writingJobAbortedError(QueryExecutionErrors.scala:749)
at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2(WriteToDataSourceV2Exec.scala:409)
at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2$(WriteToDataSourceV2Exec.scala:353)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec.writeWithV2(WriteToDataSourceV2Exec.scala:302)
at org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2Exec.run(WriteToDataSourceV2Exec.scala:313)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:43)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:43)
at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.executeCollect(V2CommandExec.scala:49)
at org.apache.spark.sql.Dataset.collectFromPlan(Dataset.scala:3868)
at org.apache.spark.sql.Dataset.$anonfun$collect$1(Dataset.scala:3120)
at org.apache.spark.sql.Dataset.$anonfun$withAction$2(Dataset.scala:3858)
at org.apache.spark.sql.execution.QueryExecution$.withInternalError(QueryExecution.scala:510)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3856)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:109)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:169)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:95)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3856)
at org.apache.spark.sql.Dataset.collect(Dataset.scala:3120)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.$anonfun$runBatch$17(MicroBatchExecution.scala:663)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:109)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:169)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:95)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.$anonfun$runBatch$16(MicroBatchExecution.scala:658)
at org.apache.spark.sql.execution.streaming.ProgressReporter.reportTimeTaken(ProgressReporter.scala:375)
at org.apache.spark.sql.execution.streaming.ProgressReporter.reportTimeTaken$(ProgressReporter.scala:373)
at org.apache.spark.sql.execution.streaming.StreamExecution.reportTimeTaken(StreamExecution.scala:68)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.runBatch(MicroBatchExecution.scala:658)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.$anonfun$runActivatedStream$2(MicroBatchExecution.scala:255)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.scala:18)
at org.apache.spark.sql.execution.streaming.ProgressReporter.reportTimeTaken(ProgressReporter.scala:375)
at org.apache.spark.sql.execution.streaming.ProgressReporter.reportTimeTaken$(ProgressReporter.scala:373)
at org.apache.spark.sql.execution.streaming.StreamExecution.reportTimeTaken(StreamExecution.scala:68)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.$anonfun$runActivatedStream$1(MicroBatchExecution.scala:218)
at org.apache.spark.sql.execution.streaming.ProcessingTimeExecutor.execute(TriggerExecutor.scala:67)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.runActivatedStream(MicroBatchExecution.scala:212)
at org.apache.spark.sql.execution.streaming.StreamExecution.$anonfun$runStream$1(StreamExecution.scala:307)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.scala:18)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)
at org.apache.spark.sql.execution.streaming.StreamExecution.org$apache$spark$sql$execution$streaming$StreamExecution$$runStream(StreamExecution.scala:285)
... 1 more
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0) (LHTU05CG050CC8Q.ms.ds.uhc.com executor driver): java.lang.NoSuchMethodError: org.apache.spark.sql.kafka010.consumer.InternalKafkaConsumerPool$PoolConfig.setMinEvictableIdleTime(Ljava/time/Duration;)V
at org.apache.spark.sql.kafka010.consumer.InternalKafkaConsumerPool$PoolConfig.init(InternalKafkaConsumerPool.scala:186)
at org.apache.spark.sql.kafka010.consumer.InternalKafkaConsumerPool$PoolConfig.<init>(InternalKafkaConsumerPool.scala:163)
at org.apache.spark.sql.kafka010.consumer.InternalKafkaConsumerPool.<init>(InternalKafkaConsumerPool.scala:54)
at org.apache.spark.sql.kafka010.consumer.KafkaDataConsumer$.<clinit>(KafkaDataConsumer.scala:637)
at org.apache.spark.sql.kafka010.KafkaBatchPartitionReader.<init>(KafkaBatchPartitionReader.scala:53)
at org.apache.spark.sql.kafka010.KafkaBatchReaderFactory$.createReader(KafkaBatchPartitionReader.scala:41)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.advanceToNextIter(DataSourceRDD.scala:84)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:63)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator$$anon$9.hasNext(Iterator.scala:576)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.$anonfun$run$1(WriteToDataSourceV2Exec.scala:435)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1538)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:480)
at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.$anonfun$writeWithV2$2(WriteToDataSourceV2Exec.scala:381)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2672)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2608)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2607)
at scala.collection.immutable.List.foreach(List.scala:333)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2607)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1182)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1182)
at scala.Option.foreach(Option.scala:437)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1182)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2860)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2802)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2791)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:952)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2228)
at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2(WriteToDataSourceV2Exec.scala:377)
... 42 more
Caused by: java.lang.NoSuchMethodError: org.apache.spark.sql.kafka010.consumer.InternalKafkaConsumerPool$PoolConfig.setMinEvictableIdleTime(Ljava/time/Duration;)V
at org.apache.spark.sql.kafka010.consumer.InternalKafkaConsumerPool$PoolConfig.init(InternalKafkaConsumerPool.scala:186)
at org.apache.spark.sql.kafka010.consumer.InternalKafkaConsumerPool$PoolConfig.<init>(InternalKafkaConsumerPool.scala:163)
at org.apache.spark.sql.kafka010.consumer.InternalKafkaConsumerPool.<init>(InternalKafkaConsumerPool.scala:54)
at org.apache.spark.sql.kafka010.consumer.KafkaDataConsumer$.<clinit>(KafkaDataConsumer.scala:637)
at org.apache.spark.sql.kafka010.KafkaBatchPartitionReader.<init>(KafkaBatchPartitionReader.scala:53)
at org.apache.spark.sql.kafka010.KafkaBatchReaderFactory$.createReader(KafkaBatchPartitionReader.scala:41)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.advanceToNextIter(DataSourceRDD.scala:84)
at org.apache.spark.sql.execution.datasources.v2.DataSourceRDD$$anon$1.hasNext(DataSourceRDD.scala:63)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator$$anon$9.hasNext(Iterator.scala:576)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.$anonfun$run$1(WriteToDataSourceV2Exec.scala:435)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1538)
at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:480)
at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.$anonfun$writeWithV2$2(WriteToDataSourceV2Exec.scala:381)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)我正在intellij中运行这个
回答 3
Stack Overflow用户
发布于 2022-08-08 06:34:31
我将spark的版本从3.3.0降至3.2.2,Scala版本2.13.8保持不变。对我来说,Scala版本2.13似乎与SparkVersion3.3.0不兼容。现在,我能够将Avro数据写入文件。
和感谢@OneCricketeer,感谢您迄今为止的帮助和支持!
Stack Overflow用户
发布于 2022-07-27 22:39:11
我无法重现错误(使用最新的IntelliJ终极版),但是下面是POM和代码
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cricket.jomoore</groupId>
<artifactId>scala</artifactId>
<version>0.1-SNAPSHOT</version>
<name>SOReady4Spark</name>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.compat.version>2.13</scala.compat.version>
<scala.version>${scala.compat.version}.8</scala.version>
<spark.version>3.3.0</spark.version>
<spec2.version>4.2.0</spec2.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-bom</artifactId>
<version>2.18.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.compat.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.compat.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.compat.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Test -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.8.2</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<!-- see http://davidb.github.com/scala-maven-plugin -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.7.1</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.0.0-M7</version>
</plugin>
</plugins>
</build>
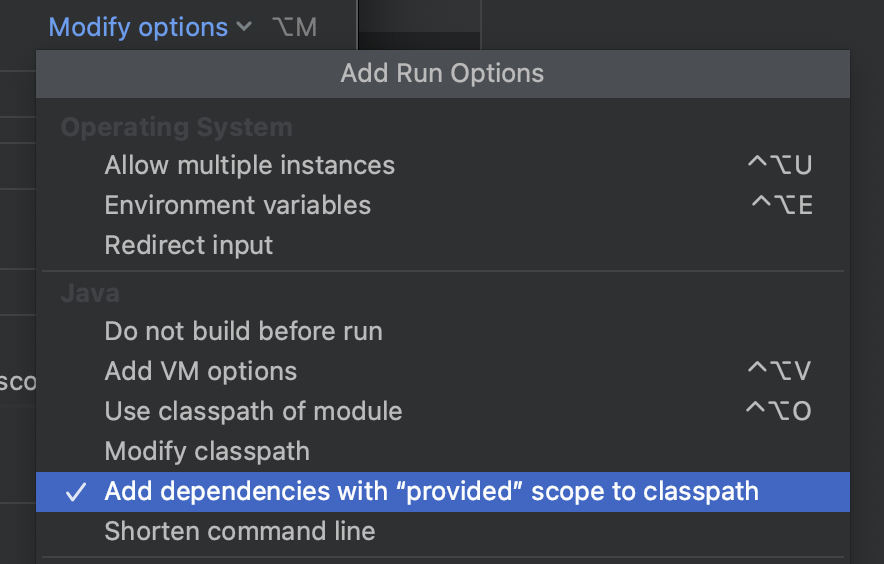
</project>当您实际将火花代码部署到一个真正的星火库集群时,需要使用<scope>provided</scope>标记。为此,还需要配置IntelliJ运行配置。
package cricketeer.one;
import org.apache.kafka.clients.consumer.OffsetResetStrategy
import org.apache.spark.sql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.types.{DataType, DataTypes}
import org.slf4j.LoggerFactory
object KafkaTest extends App {
val logger = LoggerFactory.getLogger(getClass)
/**
* For testing output to a console.
*
* @param df A Streaming DataFrame
* @return A DataStreamWriter
*/
private def streamToConsole(df: sql.DataFrame) = {
df.writeStream.outputMode(OutputMode.Append()).format("console")
}
private def getKafkaDf(spark: SparkSession, bootstrap: String, topicPattern: String, offsetResetStrategy: OffsetResetStrategy = OffsetResetStrategy.EARLIEST) = {
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", bootstrap)
.option("subscribe", topicPattern)
.option("startingOffsets", offsetResetStrategy.toString.toLowerCase())
.load()
}
val spark = SparkSession.builder()
.appName("Kafka Test")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val kafkaBootstrap = "localhost:9092"
val df = getKafkaDf(spark, kafkaBootstrap, "input-topic")
streamToConsole(
df.select($"value".cast(DataTypes.StringType))
).start().awaitTermination()
}- src/main/resources/log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Appenders>
<Console name="STDOUT" target="SYSTEM_OUT">
<PatternLayout pattern="%d %-5p [%t] %C{2} (%F:%L) - %m%n"/>
</Console>
</Appenders>
<Loggers>
<Logger name="org.apache.kafka.clients.consumer.internals.Fetcher" level="warn">
<AppenderRef ref="STDOUT"/>
</Logger>
<Root level="info">
<AppenderRef ref="STDOUT"/>
</Root>
</Loggers>
</Configuration>Stack Overflow用户
发布于 2022-08-27 00:58:44
我在Spark3.3.0中也遇到了同样的问题。我做了一些深入研究,最后找到了根本原因: Spark 3.3.0内置了对commons v.1.5.4 (Commons-Point-1.5.4.jar)的依赖,而这个结构流库依赖于v2.11.1,后者用setMinEvictableIdleTime代替了setMinEvictableIdleTime。因此,解决方案是向您的Spark文件夹中添加公共资源池2-2.11.1.jar。这个jar可以从Maven central https://repo1.maven.org/maven2/org/apache/commons/commons-pool2/2.11.1/commons-pool2-2.11.1.jar下载。
如果您想了解更多信息,我已经在页面上记录了详细信息:https://kontext.tech/article/1178/javalangnosuchmethoderror-poolconfigsetminevictableidletime
https://stackoverflow.com/questions/73139252
复制相似问题
腾讯云开发者
