相同文件下载
相同文件下载
提问于 2022-07-30 13:39:02
我有一个问题,我的脚本,以便相同的文件名,和pdf正在下载。在没有下载文件的情况下,我检查了结果的输出,得到了唯一的数据。当我使用管道时,它会以某种方式产生副本供下载。
这是我的剧本:
import scrapy
from environment.items import fcpItem
class fscSpider(scrapy.Spider):
name = 'fsc'
start_urls = ['https://fsc.org/en/members']
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(
url,
callback = self.parse
)
def parse(self, response):
content = response.xpath("(//div[@class='content__wrapper field field--name-field-content field--type-entity-reference-revisions field--label-hidden field__items']/div[@class='content__item even field__item'])[position() >1]")
loader = fcpItem()
names_add = response.xpath(".//div[@class = 'field__item resource-item']/article//span[@class='media-caption file-caption']/text()").getall()
url = response.xpath(".//div[@class = 'field__item resource-item']/article/div[@class='actions']/a//@href").getall()
pdf=[response.urljoin(x) for x in url if '#' is not x]
names = [x.split(' ')[0] for x in names_add]
for nm, pd in zip(names, pdf):
loader['names'] = nm
loader['pdfs'] = [pd]
yield loaderitems.py
class fcpItem(scrapy.Item):
names = Field()
pdfs = Field()
results = Field()pipelines.py
class DownfilesPipeline(FilesPipeline):
def file_path(self, request, response=None, info=None, item=None):
items = item['names']+'.pdf'
return itemssettings.py
from pathlib import Path
import os
BASE_DIR = Path(__file__).resolve().parent.parent
FILES_STORE = os.path.join(BASE_DIR, 'fsc')
ROBOTSTXT_OBEY = False
FILES_URLS_FIELD = 'pdfs'
FILES_RESULT_FIELD = 'results'
ITEM_PIPELINES = {
'environment.pipelines.pipelines.DownfilesPipeline': 150
}回答 2
Stack Overflow用户
回答已采纳
发布于 2022-07-30 23:56:25
问题是,每次迭代都要覆盖相同的擦伤项。
您需要做的是在每次解析方法生成时创建一个新项。我已经测试过这一点,并确认它确实产生了你想要的结果。
在下面的示例中,我在需要更改的行上创建和内联。
例如:
import scrapy
from environment.items import fcpItem
class fscSpider(scrapy.Spider):
name = 'fsc'
start_urls = ['https://fsc.org/en/members']
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(
url,
callback = self.parse
)
def parse(self, response):
content = response.xpath("(//div[@class='content__wrapper field field--name-field-content field--type-entity-reference-revisions field--label-hidden field__items']/div[@class='content__item even field__item'])[position() >1]")
names_add = response.xpath(".//div[@class = 'field__item resource-item']/article//span[@class='media-caption file-caption']/text()").getall()
url = response.xpath(".//div[@class = 'field__item resource-item']/article/div[@class='actions']/a//@href").getall()
pdf=[response.urljoin(x) for x in url if '#' is not x]
names = [x.split(' ')[0] for x in names_add]
for nm, pd in zip(names, pdf):
loader = fcpItem() # Here you create a new item each iteration
loader['names'] = nm
loader['pdfs'] = [pd]
yield loaderStack Overflow用户
发布于 2022-07-31 00:09:46
我使用的是css而不是xpath。
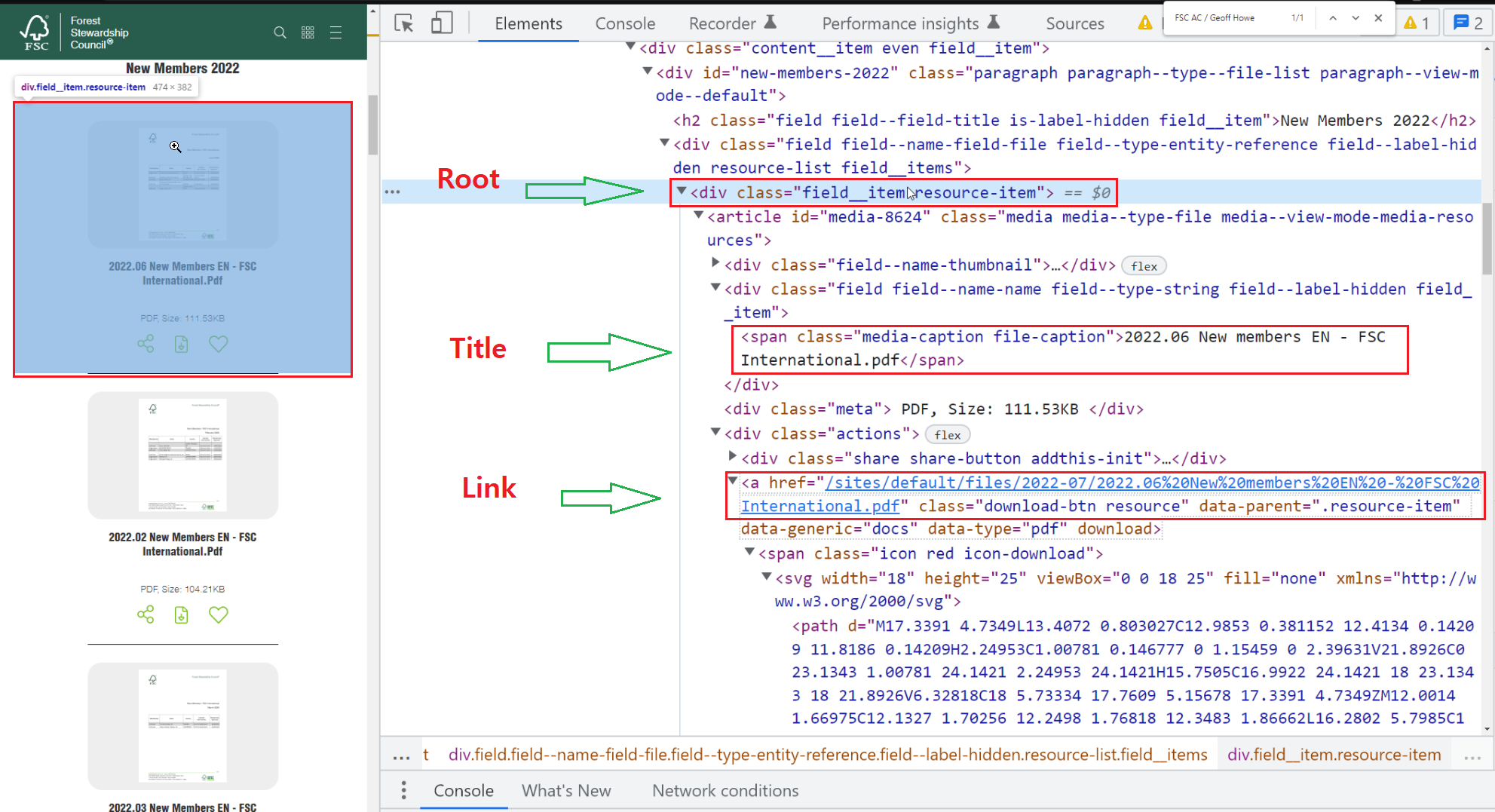
在chrome调试面板中,标签是PDF列表项的根。在该div标签下有PDF和标签标题,用于文件下载URL,根标签和标签之间有两个子和兄弟关系,所以xpath不是干净的方法,很难,一个css更好的是可以从根抓取到。它不需要有关系的路径。css可以跳过关系,只是子/或大潜艇是无关紧要的。它还提供了不必要的考虑索引问题,即URL数组和标题数组同步的索引匹配。
其他的关键点是URL路径解码和file_urls需要设置数组类型,即使单个项目。
fsc_spider.py
import scrapy
import urllib.parse
from quotes.items import fcpItem
class fscSpider(scrapy.Spider):
name = 'fsc'
start_urls = [
'https://fsc.org/en/members',
]
def parse(self, response):
for book in response.css('div.field__item.resource-item'):
url = urllib.parse.unquote(book.css('div.actions a::attr(href)').get(), encoding='utf-8', errors='replace')
url_left = url[0:url.rfind('/')]+'/'
title = book.css('span.media-caption.file-caption::text').get()
item = fcpItem()
item['original_file_name'] = title.replace(' ','_')
item['file_urls'] = ['https://fsc.org'+url_left+title.replace(' ','%20')]
yield itemitems.py
import scrapy
class fcpItem(scrapy.Item):
file_urls = scrapy.Field()
files = scrapy.Field
original_file_name = scrapy.Field()pipelines.py
import scrapy
from scrapy.pipelines.files import FilesPipeline
class fscPipeline(FilesPipeline):
def file_path(self, request, response=None, info=None):
file_name: str = request.url.split("/")[-1].replace('%20','_')
return file_namesettings.py
BOT_NAME = 'quotes'
FILES_STORE = 'downloads'
SPIDER_MODULES = ['quotes.spiders']
NEWSPIDER_MODULE = 'quotes.spiders'
FEED_EXPORT_ENCODING = 'utf-8'
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = { 'quotes.pipelines.fscPipeline': 1}文件结构
执行
quotes>scrapy crawl fsc结果

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73176091
复制相关文章
相似问题
腾讯云开发者
