
如何在python中使用base64编码和解码docx文件
我试图对docx文件进行编码,并将其解码/传递到流光中的前端/用户界面上。到目前为止,我知道如何使用base64对字符串进行编码/解码,而不是使用docx文件。
如果你们中有谁有关于如何实现它的代码的话。请在这里分享。
import base64
import streamlit as st
data = open('/home/lungsang/Desktop/streamlit-practice/content/A0/A0.02-vocab.docx', 'rb').read()
encoded = base64.b64encode(data)
decoded = base64.b64decode(encoded)
st.download_button('Download Here', decoded)我使用了上面的代码,但没有得到想要的结果。相反,我得到了.xml文件的集合。如下图所示
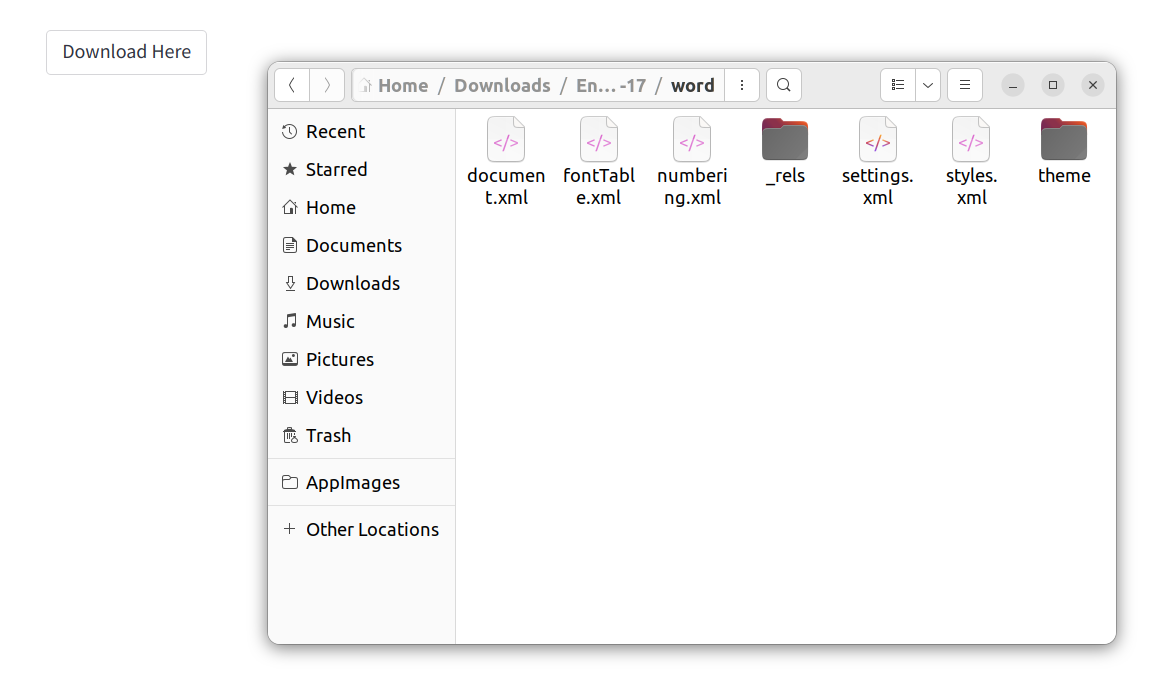
被解码的文件应该是这样的。
如果你们需要我试图编码/解码的docx文件,下面是链接https://docs.google.com/document/d/10zkg1HLDHhZNh83i2tbJqBVMfIsdqW-3/edit
回答 2
Stack Overflow用户
发布于 2022-08-03 08:23:40
您需要向filename函数中添加download_button参数
import base64
import streamlit as st
data = open("test.docx", "rb").read()
encoded = base64.b64encode(data)
decoded = base64.b64decode(encoded)
st.download_button('Download Here', decoded, "decoded_file.docx")Stack Overflow用户
发布于 2022-08-03 09:10:49
这只是编码,你必须解码
with open('YOUR DATA FILE', 'rb') as binary_file:
binary_file_data = binary_file.read()
base64_encoded_data = base64.b64encode(binary_file_data)
base64_message = base64_encoded_data.decode('utf-8')
print(base64_message)使用open打开文件(‘您的数据文件’,'rb')。注意我们是如何传递'rb‘参数和文件路径的--这告诉Python我们正在读取一个二进制文件。不使用'rb',它将假定我们正在读取文本文件.
使用read()方法将文件中的所有数据输入binary_file_data变量。类似于我们处理字符串的方式,我们使用Base64 64.b64encode对字节进行Base64编码,然后使用base64_encoded_data上的解码(‘utf-8’)来使用人类可读的字符获取Base64编码的数据。
执行代码将产生类似的输出:
python3 encoding_binary.pyhttps://stackoverflow.com/questions/73218310
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号