
基于非加权数据的加权gt表的修改
基于非加权数据的加权gt表的修改
提问于 2022-08-03 18:08:32
我正在创建多个带有多个变量的加权表,我很好奇是否可以根据未加权的值来更改加权值。具体来说,当n<2时,用NA替换单元格。
示例数据:
df <- data.frame(a= c("m","f","f","m", "m", "f", "f"),b= c("g1","g2","g1","g2", "g2", "g2", "g2"),
weight = c(1.1, 0.8, 2.2, 4, 3, 0.3, 1.9))
> df
a b weight
1 m g1 1.1
2 f g2 0.8
3 f g1 2.2
4 m g2 4.0
5 m g2 3.0
6 f g2 0.3
7 f g2 1.9表:
library(gtsummary)
library(srvyr)
tbl_summary_object <- df %>%
as_survey_design(1, weight = weight) %>%
gtsummary::tbl_svysummary(
missing="no",
by=a,
include=-weight,
label=list(
b ~ "group"
),
percent="row"
)

我希望基于未加权的单元来修改单元:
> table(df$a, df$b)
g1 g2
f 1 3
m 1 2我知道"by“未加权变量可以访问tbl_summary_object$df_by。但是,我希望根据n<2在未加权数据中更改每个单元。任何指示都将不胜感激。
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-08-03 19:27:52
我们可以使用modify_table_body
library(dplyr)
library(gtsummary)
tbl_summary_object %>%
modify_table_body(
~ .x %>%
mutate(across(starts_with('stat_'),
~ case_when(readr::parse_number(.x) >1 ~ .x))))-output
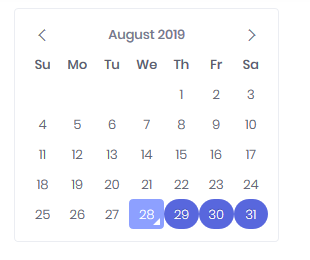
根据这些评论,也许这会有所帮助
library(tidyr)
tbl1 <- df %>%
count(a, b) %>%
mutate(a = recode(a, f = 'stat_1', m = 'stat_2')) %>%
pivot_wider(names_from = a, values_from = n)
tbl_summary_object %>%
modify_table_body(
~ .x %>%
mutate(across(starts_with('stat_'),
~ case_when(readr::parse_number(.x) > c(NA, tbl1[[cur_column()]]) ~ .x))))Stack Overflow用户
发布于 2022-08-03 18:58:24
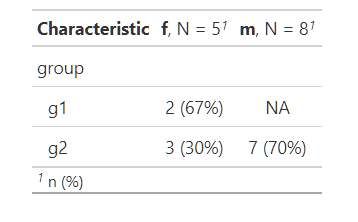
我们可以这样做:
如果我正确地理解了您的意思,那么我们可以使用tbl_summary_object[1]$table_body访问我们的对象并使用case_when来操作它,我们还使用了parse_number,它总是提取第一个数字,然后我们可以进行比较n< 2:
library(gtsummary)
library(dplyr)
library(readr) # parse_number
tbl_summary_object[1]$table_body <- tbl_summary_object[1]$table_body %>%
mutate(across(c(stat_1, stat_2), ~ case_when(parse_number(.) < 2 ~ "NA",
TRUE ~ .)))
tbl_summary_object
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73225939
复制相关文章
相似问题
腾讯云开发者
