
PySpark: TypeError: col应该是列
我正在尝试从嵌套的JSON结构中创建一个dataframe,但是我遇到了一个我不明白的问题。我已经在JSON中爆炸了一个dicts数组结构,现在我正在尝试访问这些数据集,并创建包含其中的值的列。这就是这些白痴们的样子:
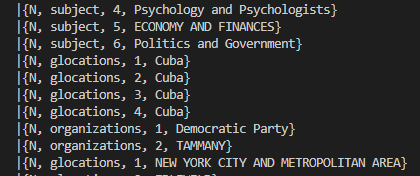
索引1(主语、位置等)处的值根据架构在键"name“下转:
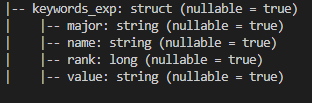
然而,当我尝试:
dataframe = dataframe.withColumn("keywords_name", dataframe.keywords_exp.name)它抛出错误:
PySpark: TypeError: col应该是列
在dict中的任何其他键都没有这样的问题,即"value“。
我真的不明白这个问题,我是否要假设数据是不一致的呢?如果是的话,你能推荐一种方法来检查甚至避开它们吗?
编辑: Khalid有一个预定义模式的好主意。我试图通过将一个JSON文件存储为一种默认文件来做到这一点。从该文件中,我想按如下方式提取模式:
schemapath = 'default_schema.json'
with open(schemapath) as f:
d = json.load(f)
schemaNew = StructType.fromJson(d)
responseDf = spark.read.schema(schemaNew).json("apiResponse.json", multiLine=True)然而,行
schemaNew = StructType.fromJson(d)抛出以下错误:
KeyError:“字段”
不知道,这些“田地”是从哪里来的.
回答 3
Stack Overflow用户
发布于 2022-08-05 15:24:54
火花中的错误说真话。
dataframe.withColumn("keywords_name", dataframe.keywords_exp.name)TypeError:col应该是列
DataFrame.withColumn文档告诉您如何调用其输入参数及其数据类型:
- Parameters:
- colName: str
字符串,新的column.
- col:列的名称。
新列的列表达式.
因此,是参数的名称,列是它的类型。Column是withColumn希望作为名为col的参数获得的数据类型。它到底收到了什么?它收到dataframe.keywords_exp.name。但是它的数据类型是什么呢?
print(type(dataframe.keywords_exp.name))
# <class 'method'>可以看出,它不是预期的类型Column.
要从Struct的字段获取列,必须使用不同的语法。
注意: dataframe中的数据类型不是您所认为的那样。你再也没有白痴了。相反,您有一个Struct类型列。旧字典中的键现在是Struct类型列的字段名。
要访问struct字段,您应该使用以下任何选项:
df = dataframe.withColumn("keywords_name", F.col("keywords_exp.name"))df = dataframe.withColumn("keywords_name", dataframe.keywords_exp['name'])( F.col("keywords_exp.name")和dataframe.keywords_exp['name']都是Column型。)
这是一个具有与您的模式相同的dataframe。您可以看到withColumn运行得很好:
from pyspark.sql import functions as F
dataframe = spark.createDataFrame(
[(("N", "glocations", 1, "Cuba"),)],
'keywords_exp struct<major:string,name:string,rank:bigint,value:string>')
dataframe.printSchema()
# root
# |-- keywords_exp: struct (nullable = true)
# | |-- major: string (nullable = true)
# | |-- name: string (nullable = true)
# | |-- rank: long (nullable = true)
# | |-- value: string (nullable = true)
df = dataframe.withColumn("keywords_name", F.col("keywords_exp.name"))
df.show()
# +--------------------+-------------+
# | keywords_exp|keywords_name|
# +--------------------+-------------+
# |{N, glocations, 1...| glocations|
# +--------------------+-------------+Stack Overflow用户
发布于 2022-08-04 11:27:34
试着在阅读前设定计划。编辑:我认为json模式需要采用特定的格式。我知道它没有很好的文档记录,但是您可以使用.json()方法提取一个示例来查看格式,然后调整模式文件。见下面更新的例子:
aa.json
[{"keyword_exp": {"name": "aa", "value": "bb"}}, {"keyword_exp": {"name": "oo", "value": "ee"}}]test.py
from pyspark.sql.session import SparkSession
import json
if __name__ == '__main__':
spark = SparkSession.builder.appName("test-app").master("local[1]").getOrCreate()
from pyspark.sql.types import StructType, StructField, StringType
schema = StructType([
StructField('keyword_exp', StructType([
StructField('name', StringType(), False),
StructField('value', StringType(), False),
])),
])
json_str = schema.json()
json_obj = json.loads(json_str)
# Save output of this as file
print(json_str)
# Just to see it pretty
print(json.dumps(json_obj, indent=4))
# Save to file
with open("file_schema.json", "w") as f:
f.write(json_str)
# Load
with open("file_schema.json", "r") as f:
scheme_obj = json.loads(f.read())
# Re-load
loaded_schema = StructType.fromJson(scheme_obj)
df = spark.read.json("./aa.json", schema=schema)
df.printSchema()
df = df.select("keyword_exp.name", "keyword_exp.value")
df.show()产出:
{"fields":[{"metadata":{},"name":"keyword_exp","nullable":true,"type":{"fields":[{"metadata":{},"name":"name","nullable":false,"type":"string"},{"metadata":{},"name":"value","nullable":false,"type":"string"}],"type":"struct"}}],"type":"struct"}
{
"fields": [
{
"metadata": {},
"name": "keyword_exp",
"nullable": true,
"type": {
"fields": [
{
"metadata": {},
"name": "name",
"nullable": false,
"type": "string"
},
{
"metadata": {},
"name": "value",
"nullable": false,
"type": "string"
}
],
"type": "struct"
}
}
],
"type": "struct"
}
root
|-- keyword_exp: struct (nullable = true)
| |-- name: string (nullable = true)
| |-- value: string (nullable = true)
+----+-----+
|name|value|
+----+-----+
| aa| bb|
| oo| ee|
+----+-----+Stack Overflow用户
发布于 2022-08-05 10:23:21
Spark似乎在某些受保护的单词上有问题。当我搜索错误信息时,我发现了这个链接。
AttributeError: ‘function’ object has no attributehttps://learn.microsoft.com/en-us/azure/databricks/kb/python/function-object-no-attribute
虽然"name“不在列表中,但我将JSON中的所有"name"-occurences更改为"nameabcde”,现在我可以访问它:
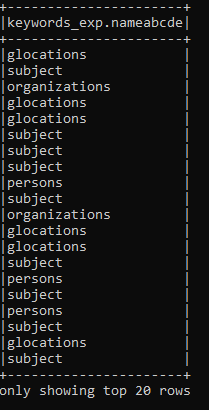
https://stackoverflow.com/questions/73233593
复制相似问题
腾讯云开发者
