
Python抓取在MLB拉中留下空白
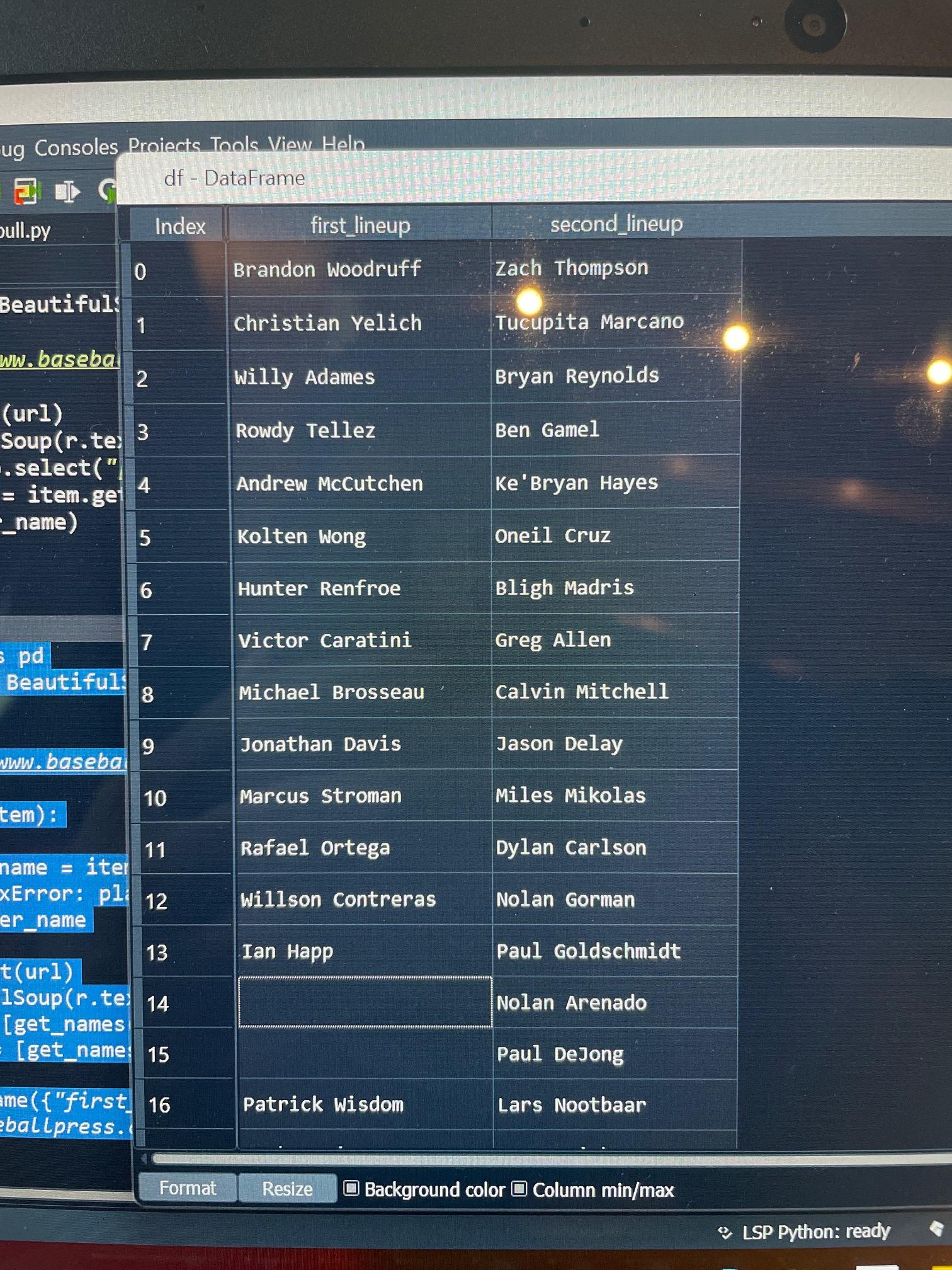
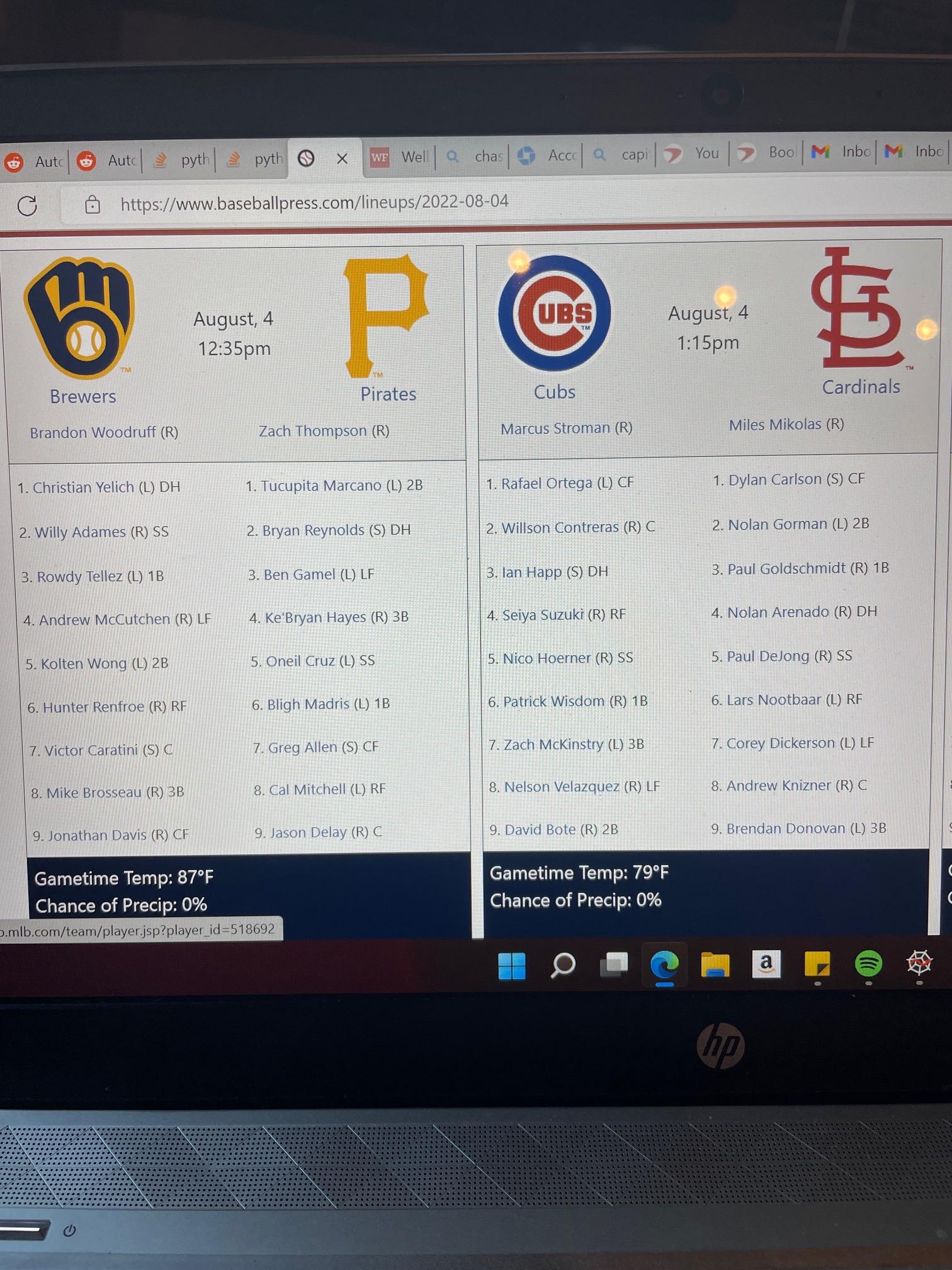
我正在尝试从这个链接中抓取MLB行:使用Python的https://www.baseballpress.com/lineups/2022-08-04。但是,当我运行下面的代码时,它会将数据提取到一个dataframe中,其中"first_lineup“列中有离开团队,"second_lineup”列中有主团队。问题是,当它将数据拉到数据中时,它并不会把每个人都拉出来。附件是数据框架和网站的截图。如果有人能帮助解释这个问题,那就太好了!谢谢。
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = "https://www.baseballpress.com/lineups/2022-08-04"
def get_names(item):
try:
player_name = item.get('data-razz').split("/")[-2].replace("+"," ")
except IndexError: player_name = ""
return player_name
r = requests.get(url)
soup = BeautifulSoup(r.text,'lxml')
first_lineup = [get_names(item) for item in soup.select(".col--min:nth-of-type(1) > a.player-link, [class$='col--min']:nth-of-type(1) .player > a.player-link")]
second_lineup = [get_names(item) for item in soup.select(".col--min:nth-of-type(2) > a.player-link, [class$='col--min']:nth-of-type(2) .player > a.player-link")]
df = pd.DataFrame({"first_lineup":first_lineup,"second_lineup":second_lineup})
df.to_csv("baseballpress.csv", encoding='utf-8', index=False)
print(df)Stack Overflow用户
发布于 2022-08-06 21:39:02
您正在为清单中的每个玩家使用data-razz属性,但是对于一些玩家,比如Suzuki,其中一些是空的,如果您看一下HTML,您会发现他和Nico都缺少这个字段。
<a class="player-link" data-bref="wisdopa01" data-mlb="621550" data-razz="https://razzball.com/player/13602/Patrick+Wisdom/" href="http://mlb.mlb.com/team/player.jsp?player_id=621550" target="_blank">Patrick Wisdom</a>
<a class="player-link" data-bref="suzukse01" data-mlb="673548" data-razz="" href="http://mlb.mlb.com/team/player.jsp?player_id=673548" target="_blank">Seiya Suzuki</a>
<a class="player-link" data-bref="hoernni01" data-mlb="663538" data-razz="" href="http://mlb.mlb.com/team/player.jsp?player_id=663538" target="_blank">Nico Hoerner</a>类似地,许多玩家,可能由于名字的长度,为desktop-name (包含全名的文本,例如Brandon Woodruff)和mobile-name (包含缩短的名称,例如B. Woodruff)提供了额外的选择器,如下所示:
<a class="player-link" data-bref="woodrbr01" data-mlb="605540" data-razz="https://razzball.com/player/605540/Brandon+Woodruff/" href="http://mlb.mlb.com/team/player.jsp?player_id=605540" target="_blank">
<span class="desktop-name">Brandon Woodruff</span>
<span class="mobile-name">B. Woodruff</span>
</a>它看起来不像您的代码,因为它特别关心实际的razzball URL,因此您可以在每个字段上调用get_text(),以获得通过<p>标记显示的播放机名称,并进行一些额外的检查,以查看播放机是否有desktop-name字段。
from bs4 import Tag
# ...stuff...
def get_player_name(t: Tag) -> str:
if span := t.find("span", {"class": "desktop-name"}):
return span.get_text()
return t.get_text()然后称之为..。
first_lineup = [get_player_name(t) for t in soup.select(".col--min:nth-of-type(1) > a.player-link, [class$='col--min']:nth-of-type(1) .player > a.player-link")]
second_lineup = [get_player_name(t) for t in soup.select(".col--min:nth-of-type(2) > a.player-link, [class$='col--min']:nth-of-type(2) .player > a.player-link")]现在你应该为每个球员取更长的名字。
https://stackoverflow.com/questions/73263306
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号