
在TensorFlow中,顺序和模型([输入],[输出])有什么区别?
当我一层一层地构建模型时,Sequential和Model([input],[output])的结果似乎是一样的。但是,当我使用以下两个输入相同的模型时,它们给出了不同的results.By方式,输入形状是(None, 15, 2),输出形状是(None, 1, 2)。
Sequential模型:
model = tf.keras.Sequential(
[
tf.keras.layers.Conv1D(filters = 4, kernel_size =7, activation = "relu"),
tf.keras.layers.Conv1D(filters = 6, kernel_size = 11, activation = "relu"),
tf.keras.layers.LSTM(100, return_sequences=True,activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.LSTM(100,activation='relu'),
tf.keras.layers.Dense(2,activation='relu'),
tf.keras.layers.Reshape((1,2))
]
)Model([input],[output])模型
input_layer = tf.keras.layers.Input(shape=(LOOK_BACK, 2))
conv = tf.keras.layers.Conv1D(filters=4, kernel_size=7, activation='relu')(input_layer)
conv = tf.keras.layers.Conv1D(filters=6, kernel_size=11, activation='relu')(conv)
lstm = tf.keras.layers.LSTM(100, return_sequences=True, activation='relu')(conv)
dropout = tf.keras.layers.Dropout(0.2)(lstm)
lstm = tf.keras.layers.LSTM(100, activation='relu')(dropout)
dense = tf.keras.layers.Dense(2, activation='relu')(lstm)
output_layer = tf.keras.layers.Reshape((1,2))(dense)
model = tf.keras.models.Model([input_layer], [output_layer])Sequential模型的结果:
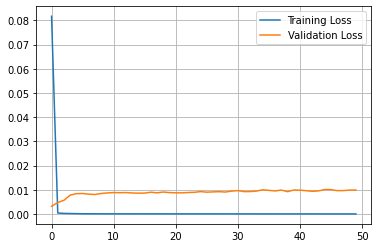
mse: 21.679258038588586
rmse: 4.65609901511862
mae: 3.963341420395535
Model([input],[output])模型的结果如下:
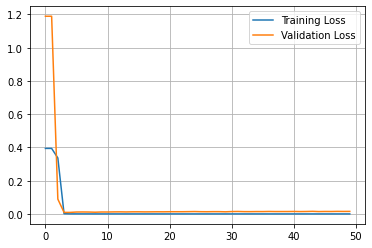
mse: 36.85855652774293
rmse: 6.071124815694612
mae: 4.4878270279889065
回答 1
Stack Overflow用户
发布于 2022-08-07 04:59:12
Sequence版本使用序列模型,而Model([inputs], [outputs])使用功能API。
第一种更容易使用,但只适用于单输入单输出前馈模型(在Keras层的意义上)。
第二个更复杂,但摆脱了这些约束,允许创建更多的模型。
所以,你的主要观点是正确的:任何序列模型都可以重写为一个功能模型。您可以通过比较架构与函数和绘制模型的使用情况来反复检查这一点。
然而,这只表明架构是相同的,而不是权重!
假设您用相同的数据以及相同的compile和fit参数来拟合这两个模型(顺便说一句,包括您的问题中的那些),那么在培训过程中会有很多的随机性,这可能会导致不同的结果。因此,尝试下面的来更好地比较它们的:
- 通过在代码中设置种子和为每一层实例化消除尽可能多的随机性。
- 避免使用数据增强(如果使用)。
- 对两个模型使用相同的验证/训练拆分:要确定,您可以自己拆分数据集。
- 不要在数据生成器中或在培训期间使用洗牌。
这里你可以读到更多关于在角膜中产生可重复结果的内容。
即使在遵循这些提示之后,您的结果也可能是不确定的,因此结果可能不一样,因此,最后,也许更重要的一点是:不要比较单个运行:不要对每个模型进行多次(例如,20)的训练和评估,然后将平均MAE与其标准差进行比较。
如果你的结果仍然是如此不同,请用它们来更新你的问题。
https://stackoverflow.com/questions/73264482
复制相似问题
腾讯云开发者
