
如何与拥抱面板的训练器api并行运行端到端的分布式数据示例(最好是在单个节点、多个gpus上)?
如何与拥抱面板的训练器api并行运行端到端的分布式数据示例(最好是在单个节点、多个gpus上)?
提问于 2022-08-17 15:35:11
我广泛地浏览了互联网,拥抱了face的讨论论坛&回购,但没有找到如何正确处理与HF并行的ddp/分布式数据的最终例子(链接在末尾)。
这就是我所需要的,能够端到端地运行它:
,
- ,我们是否将hf模型封装在DDP中?(脚本需要知道如何在某个地方同步一些东西,否则只需从命令行启动torch.distributed ),
- ,我们是否将args更改为训练器或训练器?将优化器封装在任何分布式培训器中(比如樱桃?)cherry是一种类似
python -m torch.distributed.launch --nproc_per_node=2 distributed_maml.py - how的
- ,我们做的是通常需要的init组吗?
- ,本地排名的角色是什么?
- 终端启动脚本,例如,我们是否使用世界大小在每个循环中分割数据?参见https://github.com/learnables/learn2learn/blob/master/examples/vision/distributed_maml.py
给出答案,我想我可以写我自己的笔记本,并广泛分享。
这是我想要完成的初学者代码,但不确定我是否做得对(特别是我不知道该修改哪个args ):
"""
- training on multiple gpus: https://huggingface.co/docs/transformers/perf_train_gpu_many#efficient-training-on-multiple-gpus
- data paralelism, dp vs ddp: https://huggingface.co/docs/transformers/perf_train_gpu_many#data-parallelism
- github example: https://github.com/huggingface/transformers/tree/main/examples/pytorch#distributed-training-and-mixed-precision
- above came from hf discuss: https://discuss.huggingface.co/t/using-transformers-with-distributeddataparallel-any-examples/10775/7
⇨ Single Node / Multi-GPU
Model fits onto a single GPU:
DDP - Distributed DP
ZeRO - may or may not be faster depending on the situation and configuration used.
...https://huggingface.co/docs/transformers/perf_train_gpu_many#scalability-strategy
python -m torch.distributed.launch \
--nproc_per_node number_of_gpu_you_have path_to_script.py \
--all_arguments_of_the_script
python -m torch.distributed.launch --nproc_per_node 2 main_data_parallel_ddp_pg.py
python -m torch.distributed.launch --nproc_per_node 2 ~/ultimate-utils/tutorials_for_myself/my_hf_hugging_face_pg/main_data_parallel_ddp_pg.py
e.g.
python -m torch.distributed.launch \
--nproc_per_node 8 pytorch/text-classification/run_glue.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--task_name mnli \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 8 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--output_dir /tmp/mnli_output/
"""
# %%
# - init group
# - set up processes a la l2l
# local_rank: int = local_rank: int = int(os.environ["LOCAL_RANK"]) # get_local_rank()
# print(f'{local_rank=}')
## init_process_group_l2l(args, local_rank=local_rank, world_size=args.world_size, init_method=args.init_method)
# init_process_group_l2l bellow
# if is_running_parallel(rank):
# print(f'----> setting up rank={rank} (with world_size={world_size})')
# # MASTER_ADDR = 'localhost'
# MASTER_ADDR = '127.0.0.1'
# MASTER_PORT = master_port
# # set up the master's ip address so this child process can coordinate
# os.environ['MASTER_ADDR'] = MASTER_ADDR
# print(f"---> {MASTER_ADDR=}")
# os.environ['MASTER_PORT'] = MASTER_PORT
# print(f"---> {MASTER_PORT=}")
#
# # - use NCCL if you are using gpus: https://pytorch.org/tutorials/intermediate/dist_tuto.html#communication-backends
# if torch.cuda.is_available():
# backend = 'nccl'
# # You need to call torch_uu.cuda.set_device(rank) before init_process_group is called. https://github.com/pytorch/pytorch/issues/54550
# torch.cuda.set_device(
# args.device) # is this right if we do parallel cpu? # You need to call torch_uu.cuda.set_device(rank) before init_process_group is called. https://github.com/pytorch/pytorch/issues/54550
# print(f'---> {backend=}')
# rank: int = torch.distributed.get_rank() if is_running_parallel(local_rank) else -1
# https://huggingface.co/docs/transformers/tasks/translation
import datasets
from datasets import load_dataset, DatasetDict
books: DatasetDict = load_dataset("opus_books", "en-fr")
print(f'{books=}')
books: DatasetDict = books["train"].train_test_split(test_size=0.2)
print(f'{books=}')
print(f'{books["train"]=}')
print(books["train"][0])
"""
{'id': '90560',
'translation': {'en': 'But this lofty plateau measured only a few fathoms, and soon we reentered Our Element.',
'fr': 'Mais ce plateau élevé ne mesurait que quelques toises, et bientôt nous fûmes rentrés dans notre élément.'}}
"""
# - t5 tokenizer
from transformers import AutoTokenizer, PreTrainedTokenizerFast, PreTrainedTokenizer
tokenizer: PreTrainedTokenizerFast = AutoTokenizer.from_pretrained("t5-small")
print(f'{isinstance(tokenizer, PreTrainedTokenizer)=}')
print(f'{isinstance(tokenizer, PreTrainedTokenizerFast)=}')
source_lang = "en"
target_lang = "fr"
prefix = "translate English to French: "
def preprocess_function(examples):
inputs = [prefix + example[source_lang] for example in examples["translation"]]
targets = [example[target_lang] for example in examples["translation"]]
model_inputs = tokenizer(inputs, max_length=128, truncation=True)
with tokenizer.as_target_tokenizer():
labels = tokenizer(targets, max_length=128, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
# Then create a smaller subset of the dataset as previously shown to speed up the fine-tuning: (hack to seep up tutorial)
books['train'] = books["train"].shuffle(seed=42).select(range(100))
books['test'] = books["test"].shuffle(seed=42).select(range(100))
# # use Datasets map method to apply a preprocessing function over the entire dataset:
# tokenized_datasets = dataset.map(tokenize_function, batched=True, batch_size=2)
# todo - would be nice to remove this since gpt-2/3 size you can't preprocess the entire data set...or can you?
# tokenized_books = books.map(preprocess_function, batched=True, batch_size=2)
from uutils.torch_uu.data_uu.hf_uu_data_preprocessing import preprocess_function_translation_tutorial
preprocessor = lambda examples: preprocess_function_translation_tutorial(examples, tokenizer)
tokenized_books = books.map(preprocessor, batched=True, batch_size=2)
print(f'{tokenized_books=}')
# - load model
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
# - to DDP
# model = model().to(rank)
# from torch.nn.parallel import DistributedDataParallel as DDP
# ddp_model = DDP(model, device_ids=[rank])
# Use DataCollatorForSeq2Seq to create a batch of examples. It will also dynamically pad your text and labels to the
# length of the longest element in its batch, so they are a uniform length.
# While it is possible to pad your text in the tokenizer function by setting padding=True, dynamic padding is more efficient.
from transformers import DataCollatorForSeq2Seq
# Data collator that will dynamically pad the inputs received, as well as the labels.
data_collator: DataCollatorForSeq2Seq = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model)
"""
At this point, only three steps remain:
- Define your training hyperparameters in Seq2SeqTrainingArguments.
- Pass the training arguments to Seq2SeqTrainer along with the model, dataset, tokenizer, and data collator.
- Call train() to fine-tune your model.
"""
report_to = "none"
if report_to != 'none':
import wandb
wandb.init(project="playground", entity="brando", name='run_name', group='expt_name')
from transformers import Seq2SeqTrainingArguments, Seq2SeqTrainer
# fp16 = True # cuda
# fp16 = False # cpu
import torch
fp16 = torch.cuda.is_available() # True for cuda, false for cpu
training_args = Seq2SeqTrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=1,
fp16=fp16,
report_to=report_to,
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_books["train"],
eval_dataset=tokenized_books["test"],
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.train()
print('\n ----- Success\a')在写这个问题时,我参考了所有的参考资料:
- https://discuss.huggingface.co/t/using-transformers-with-distributeddataparallel-any-examples/10775/3
- https://huggingface.co/docs/transformers/perf_train_gpu_many#scalability-strategy
- https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Trainer
- Setting Hugging Face dataloader_num_workers for multi-GPU training
- using huggingface Trainer with distributed data parallel
- Why, using Huggingface Trainer, single GPU training is faster than 2 GPUs?
- https://discuss.huggingface.co/t/lm-example-run-clm-py-isnt-distributing-data-across-multiple-gpus-as-expected/3239/6
- https://discuss.huggingface.co/t/which-data-parallel-does-trainer-use-dp-or-ddp/16021/3
- https://github.com/huggingface/transformers/tree/main/examples/pytorch#distributed-training-and-mixed-precision
- https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
- dist哺乳类:https://github.com/learnables/learn2learn/blob/master/examples/vision/distributed_maml.py
- cross:https://discuss.huggingface.co/t/how-to-run-an-end-to-end-example-of-distributed-data-parallel-with-hugging-faces-trainer-api-ideally-on-a-single-node-multiple-gpus/21750
回答 1
Stack Overflow用户
发布于 2022-08-17 19:10:57
你不需要设置任何东西,只需做:
python -m torch.distributed.launch --nproc_per_node 2 ~/src/main_debug.py然后使用nvidia-smi监视gpus,请参阅:
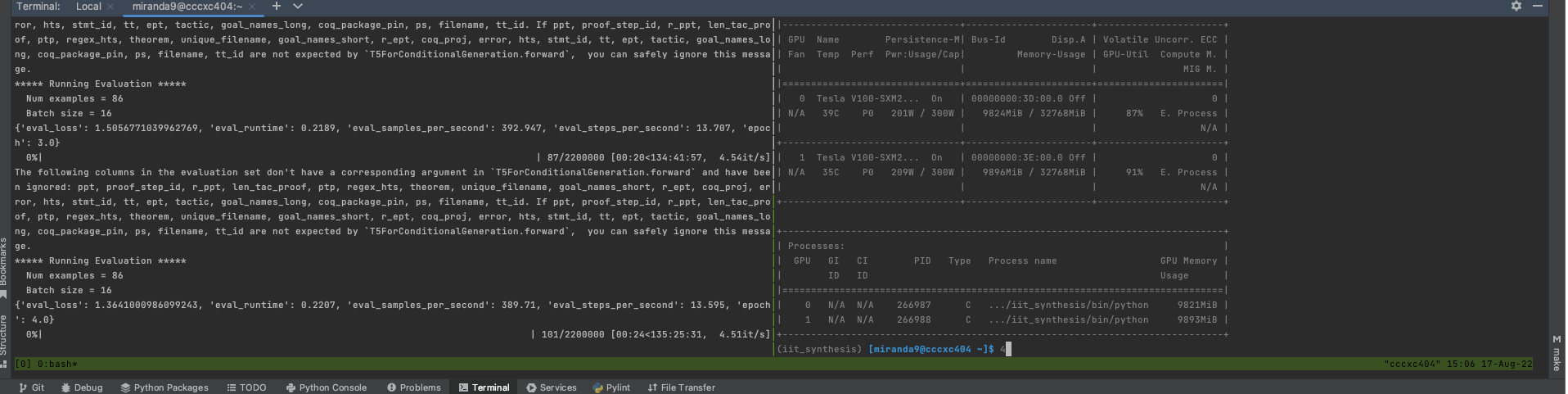
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73391230
复制相关文章
相似问题
腾讯云开发者
