
如何从sns.clustermap中提取标签
如果我正在用sns.clustermap绘制一个(相关)数据,它会自动地将dataframes多个索引作为标签,并将它们绘制在集群地图的正下方。
我如何访问这些标签?我正在使用聚类图作为大型ish数据集(100-200个条目)的探索性工具,我需要各个集群中条目的名称。
示例:
elev = [1, 100, 10, 1000, 100, 10]
number = [1, 2, 3, 4, 5, 6]
name = ['foo', 'bar', 'baz', 'qux', 'quux', 'quuux']
idx = pd.MultiIndex.from_arrays([name, elev, number],
names=('name','elev', 'number'))
data = np.random.rand(20,6)
df = pd.DataFrame(data=data, columns=idx)
clustermap = sns.clustermap(df.corr())给出
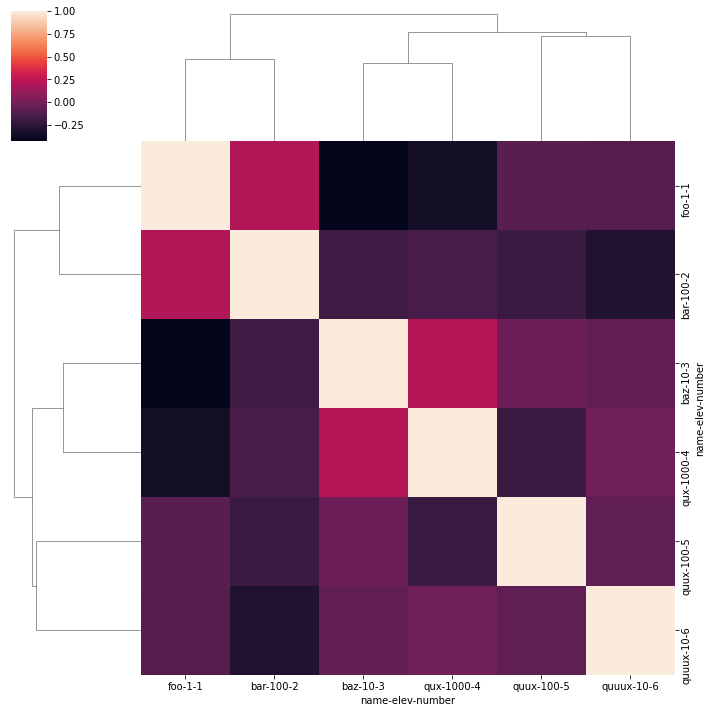
现在我要说有两个不同的集群:前两行和最后四行,因此[foo-1-1, bar-100-2]和[baz-10-3, qux-1000-4, quux-100-5, quuux-10-6]。
如何提取这些(或整个[foo-1-1, bar-100-2, baz-10-3, qux-1000-4, quux-100-5, quuux-10-6]列表)?对于100+条目,手工编写它们并不是一个真正的选择。
文档提供了clustergrid.dendrogram_row.reordered_ind,但这只是给出了原始数据中的索引号。但是我在寻找更像df.columns输出的东西
使用这,在我看来,我似乎进入了正确的方向,但是,当我让它自动形成集群时,我只能提取出一个给定行属于哪个集群,但是我希望自己直观地定义集群。
回答 1
Stack Overflow用户
发布于 2022-08-19 06:32:52
像往常一样,答案是存在的,我只是忽略了它。
这个答案 (由Trenton McKinney在注释中指出)在其中有所需的片段:
ax_heatmap.yaxis.get_majorticklabels()(我不会为了达到这个目的而调查ax_heatmap。)因此,从问题中继续进行MWE:
labels = clustermap.ax_heatmap.yaxis.get_majorticklabels()然而,这是一份清单
type(labels[0])
matplotlib.text.Text所以,除非我遗漏了一些东西(再次),否则它并不完全是向前使用的。然而,这可以简单地被循环成更有用的东西。假设我对全名(即完整的df多索引)和数字感兴趣:
labels_list = []
number_list = []
for i in labels:
i = str(i)
name_start = i.find('\'')+1
name_end = i.rfind('\'')
name = i[name_start:name_end]
number_start = name.rfind('-')+1
number = name[number_start:]
number = int(number)
labels_list.append(name)
number_list.append(number)现在,我有了两个易于操作的列表,一个包含完整的字符串,另一个包含ints。
https://stackoverflow.com/questions/73404428
复制相似问题
腾讯云开发者
