
Python熊猫和numpy:根据现有变量的多个条件为新变量分配数值
Python熊猫和numpy:根据现有变量的多个条件为新变量分配数值
提问于 2022-08-23 18:40:12
这在Excel中是微不足道的,为什么在Python中这么难呢?
目标是根据几个条件计算状态变量,包括状态变量的前一个值。值是已知的整数,Min(3)和Max(3)是3个周期滚动窗口向前移动一个周期的最小值和最大值。这就是我走了这么远。
Index Value Max(3) Min(3)
0 10 nan nan
1 20 nan nan
2 15 nan nan
3 25 20 10
4 15 25 15
5 10 25 15
6 15 20 10 根据以下条件计算状态变量的最佳方法是什么:
- ( a)如果值>最大值(3),则1
- b)如果值< Min(3)那么4
- c)如果值<= Max(3) &值>= Min (3) &先前状态=1或2,则为2
- d)如果值<= Max(3) &值>= Min (3) &前一状态=4或3,则为3
在最终的DataFrame中应该是这样的:
Index Value Max(3) Min(3) State
0 10 nan nan nan
1 20 nan nan nan
2 15 nan nan nan
3 25 20 10 1
4 15 25 15 2
5 10 25 15 4
6 15 20 10 3 我大多使用np.where()函数尝试过这种方法,但是当我接近c)和d)条件时,总是会遇到问题。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-08-23 18:58:53
你可以用这个:
df.loc[df.Value.gt(df['Max(3)']), 'State'] = 1
df.loc[df.Value.lt(df['Min(3)']), 'State'] = 4
df.loc[df.Value.between(df['Min(3)'], df['Max(3)']) & (df.State.shift(1).isin((3, 4))), 'State'] = 3
df.loc[df.Value.between(df['Min(3)'], df['Max(3)']) & (df.State.shift(1).isin((1,2))), 'State'] = 2输出:
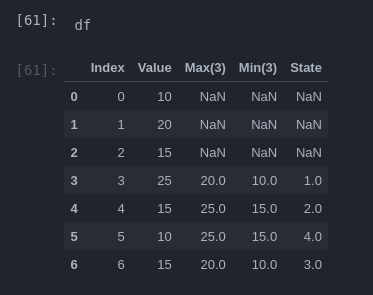
解释:
第一个语句检查df.Value是否大于df‘’Max(3)‘,并创建一个新的列'State’,其中填充了NaNs,并且在条件的位置上只有1s。
秒线设置4s,其中df.Value小于df.'Min(3)‘
最后两个语句检查df.Value是否在Max(3)和Min(3)内,并比较df.State最后值(.shift)。注意:如果数字是子序列,也可以在这里使用.between而不是.isin。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73463688
复制相关文章
相似问题
腾讯云开发者
