
如何通过指定分区将分区插入到Python中BigQuery的获取时间分区表中
摘要
如何使用Python在要获取的fetch时间分区表中指定分区?
我们试过的
我发现在SQL中插入以下内容是可能的。https://cloud.google.com/bigquery/docs/using-dml-with-partitioned-tables
但我不知道如何用Python来描述它。我正在考虑使用google模块中的"client.load_table_from_dataframe“。https://googleapis.dev/python/bigquery/latest/generated/google.cloud.bigquery.client.Client.html#google.cloud.bigquery.client.Client.load_table_from_dataframe
我找到了下面的文档,但是当我使用名称_PARTITIONTIME时,我会得到以下错误。https://cloud.google.com/bigquery/docs/samples/bigquery-load-table-partitioned#bigquery_load_table_partitioned-python
google.api_core.exceptions.BadRequest: 400 POST https://bigquery.googleapis.com/upload/bigquery/v2/projects/aaa/jobs?uploadType=multipart: Invalid field name "_PARTITIONTIME". Field names are not allowed to start with the (case-insensitive) prefixes _PARTITION, _TABLE_, _FILE_, _ROW_TIMESTAMP, __ROOT__ and _COLIDENTIFIER执行环境
3.8.10
- google-cloud-bigquery: inserted.
- python:3.2.0
- :1.4.3关于认证
- 的
- 如果没有指定分区,我们认为没有问题,因为数据可以是inserted.
表格
CREATE TABLE IF NOT EXISTS `aaa.bbb.ccc`(
c1 INTEGER,
c2 STRING
)
PARTITION BY _PARTITIONDATE;我想做什么
SQL
INSERT INTO `aaa.bbb.ccc` (c1, c2, _PARTITIONTIME) VALUES (99, "zz", TIMESTAMP("2000-01-02"));Python (尝试和测试的代码)
import pandas as pd
from google.cloud import bigquery
from google.cloud.bigquery.enums import SqlTypeNames
from google.cloud.bigquery.job import WriteDisposition
from datetime import datetime
client = bigquery.Client(project="aaa")
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("c1", SqlTypeNames.INTEGER),
bigquery.SchemaField("c2", SqlTypeNames.STRING),
bigquery.SchemaField("_PARTITIONTIME", SqlTypeNames.TIMESTAMP),
],
write_disposition=WriteDisposition.WRITE_APPEND,
time_partitioning=bigquery.TimePartitioning(
type_=bigquery.TimePartitioningType.DAY,
field="_PARTITIONTIME", # Name of the column to use for partitioning.
expiration_ms=7776000000, # 90 days.
),
)
df = pd.DataFrame(
[
[1, "a", datetime.strptime("2100-11-12", "%Y-%m-%d")],
[2, "b", datetime.strptime("2101-12-13", "%Y-%m-%d")],
],
columns=["c1", "c2", "_PARTITIONTIME"],
)
job = client.load_table_from_dataframe(df, "aaa.bbb.ccc", job_config=job_config) # error
result = job.result()多柱
回答 1
Stack Overflow用户
发布于 2022-08-30 00:46:15
您只需将命名约定_PARTITIONTIME更改为另一个名称,因为它是区分大小写的前缀的一部分。以下代码起了作用:
import pandas as pd
from google.cloud import bigquery
from google.cloud.bigquery.enums import SqlTypeNames
from google.cloud.bigquery.job import WriteDisposition
from datetime import datetime
client = bigquery.Client(project="<your-project>")
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("c1", SqlTypeNames.INTEGER),
bigquery.SchemaField("c2", SqlTypeNames.STRING),
bigquery.SchemaField("_P1", SqlTypeNames.TIMESTAMP),
],
write_disposition=WriteDisposition.WRITE_APPEND,
time_partitioning=bigquery.TimePartitioning(
type_=bigquery.TimePartitioningType.DAY,
field="_P1", # Name of the column to use for partitioning.
expiration_ms=7776000000, # 90 days.
),
)
df = pd.DataFrame(
[
[1, "a", datetime.strptime("2100-11-12", "%Y-%m-%d")],
[2, "b", datetime.strptime("2101-12-13", "%Y-%m-%d")],
],
columns=["c1", "c2", "_P1"],
)
job = client.load_table_from_dataframe(df, "<your-project>.<your-dataset>.ccc", job_config=job_config) # error
result = job.result()输出:
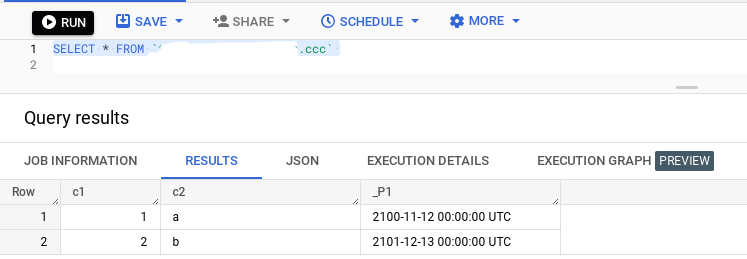
至于您想要插入的查询:
INSERT INTO `<your-project>.<your-dataset>.ccc` (c1, c2, _P1) VALUES (99, "zz", TIMESTAMP("2000-01-02"));这是不可能的,就像谷歌人在这个SO post中所解释的那样。由于在expiration_ms字段中,我们指出过期为90天,在当前日期(执行python脚本的日期)之前90天是有效日期,之前的任何日期都是无效的。此查询将工作:
INSERT INTO `<your-project>.<your-dataset>.ccc` (c1, c2, _P1) VALUES (99, "zz", TIMESTAMP("2022-06-01"));输出:
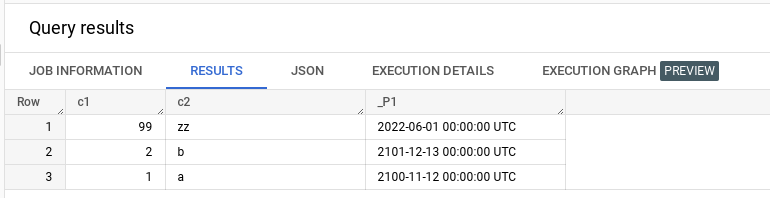
https://stackoverflow.com/questions/73523372
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号