
使用具有特定字符串的多列进行过滤,然后在R中的一列中进行变异
使用具有特定字符串的多列进行过滤,然后在R中的一列中进行变异
提问于 2022-08-31 04:27:09
data <- data.frame(
"grammer" = c("Python","C","Java","GO",NA,"SQL"),
"score" = c(1,2,NA,4,7,10),
"file" = c("GHG.txt", "GXG.ect", NA , "VAC.ect", "GBA.ect", "GHG.txt"),
"file2" = c("GHG.txt", "GXG.dat", "AGG.ect", "VAC.txt", "GBA.dat", "GHG.dat"),
"file3" = c("GHG.dat", "GXG.txt", "AGG.dat", "VAC.dat", "GBA.txt", NA )
)我希望从列(文件、file2、file3)中获得后缀file2,并在新列中进行变异。
以下是我的密码。我要换衣服同时过滤。
d1 <- data %>%
filter(str_detect(file, ".ect")) %>%
mutate(sub("\\..*", "", file))
d2 <- data %>%
filter(str_detect(file2, ".ect")) %>%
mutate(sub("\\..*", "", file2))
d3 <- data %>%
filter(str_detect(file3, ".ect")) %>%
mutate(sub("\\..*", "", file3))这是我的预期结果:
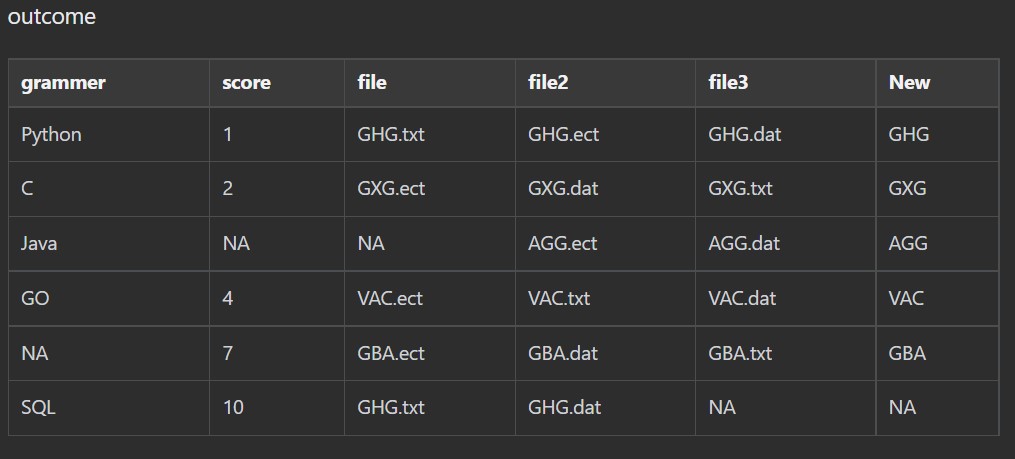
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-08-31 05:02:41
我们可以使用across
library(tidyverse)
data |>
mutate(new = apply(across(c(file, file2, file3)), 1, function(x) str_remove(str_subset(c(x), ".ect"), ".ect$")))这意味着:
grammer score file file2 file3 new
1 Python 1 GHG.txt GHG.txt GHG.dat
2 C 2 GXG.ect GXG.dat GXG.txt GXG
3 Java NA <NA> AGG.ect AGG.dat AGG
4 GO 4 VAC.ect VAC.txt VAC.dat VAC
5 <NA> 7 GBA.ect GBA.dat GBA.txt GBA
6 SQL 10 GHG.txt GHG.dat <NA> 注意,如果没有匹配,该解决方案只返回一个空字符值,即"",而屏幕截图从图到想要一个缺失的值NA。这可以通过简单的ifelse来实现,所以不要将它添加到这里的代码中。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73550870
复制相关文章
相似问题
腾讯云开发者
