
PDF到纯文本,遇到了Acrobat中的一些困难页面
基本问题::https://1drv.ms/u/s!AsrLaUgt0KCLhXtP-jYDd4Z0ujKQ?e=xSu2ZR
我无法使用Acrobat标准或批处理转换脚本(以下)手动转换/保存为纯文本。生成的文件为空。
完全问题:作为批量将PDF转换为文本的尝试的一部分,我遇到了一个奇怪的错误,其中acrobat返回以下内容:
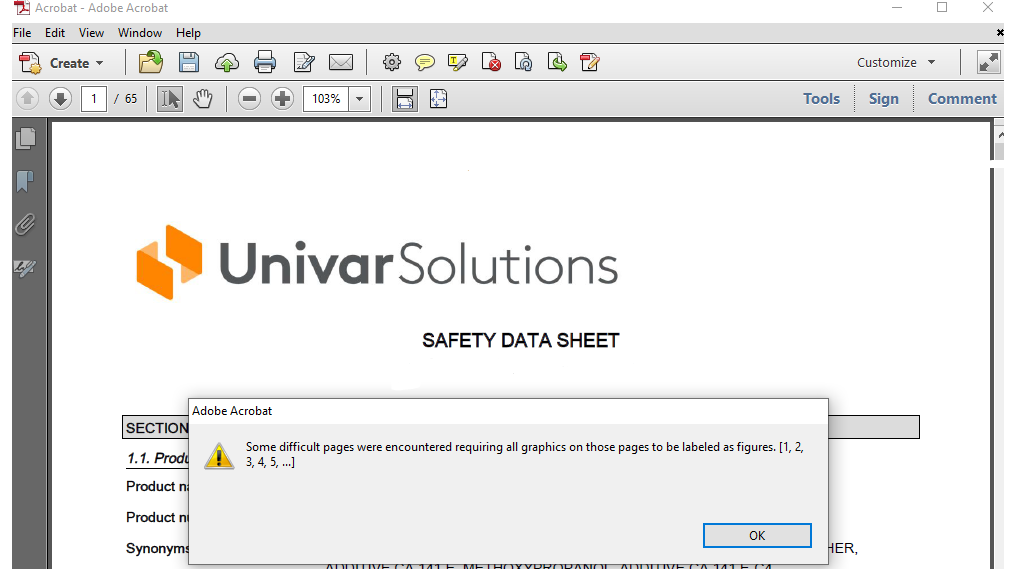
令人失望的是,单击ok生成文本文件为空白。
下面的脚本循环遍历PDF文件并使用acrobat将它们转换为文本文件:它对大多数PDF都很好,除了上面的数字。
Sub LoopThroughFiles()
Dim StrFile As String
Dim pdfPath As String
StrFile = Dir("C:\temp\PDFs\")
fileRoot = "C:\temp\PDFs\"
If Right(fileRoot, 1) <> "\" Then fileRoot = fileRoot & "\" 'ensure terminating \
Do While Len(StrFile) > 0
Debug.Print StrFile
pdfPath = fileRoot & StrFile
Debug.Print pdfPath
success = ConvertPdf2(pdfPath, fileRoot & StrFile & ".txt")
StrFile = Dir
On Error Resume Next
Loop
End Sub
'returns true if conversion was successful (based on whether `Open` succeeded or not)
Function ConvertPdf2(pdfPath As String, textPath As String) As Boolean
Dim AcroXApp As Acrobat.AcroApp
Dim AcroXAVDoc As Acrobat.AcroAVDoc
Dim AcroXPDDoc As Acrobat.AcroPDDoc
Dim jsObj As Object, success As Boolean
Set AcroXApp = CreateObject("AcroExch.App")
Set AcroXAVDoc = CreateObject("AcroExch.AVDoc")
success = AcroXAVDoc.Open(pdfPath, "Acrobat") '<<< returns false if fails
If success Then
Application.Wait (Now + TimeValue("0:00:2")) 'Helps PC have some time to go through data, can cause PC to freeze without
Set AcroXPDDoc = AcroXAVDoc.GetPDDoc
Set jsObj = AcroXPDDoc.GetJSObject
jsObj.SaveAs textPath, "com.adobe.acrobat.plain-text"
AcroXAVDoc.Close False
End If
AcroXApp.Hide
AcroXApp.Exit
ConvertPdf2 = success 'report success/failure
End Function错误似乎是jsObj.SaveAs textPath, "com.adobe.acrobat.plain-text",如果我使用jsObj.SaveAs textPath,则生成文本文件,但出于我的需要,文件生成的格式是纯文本格式。
其原因可以在下面的另一个PDF中看到。这些是生成的不同类型的文本文件:
纯文本(在水平方向扩展为句子-这是必需的):

访问文本:(创建更多的文本-通过回车分隔句子,这是有问题的)
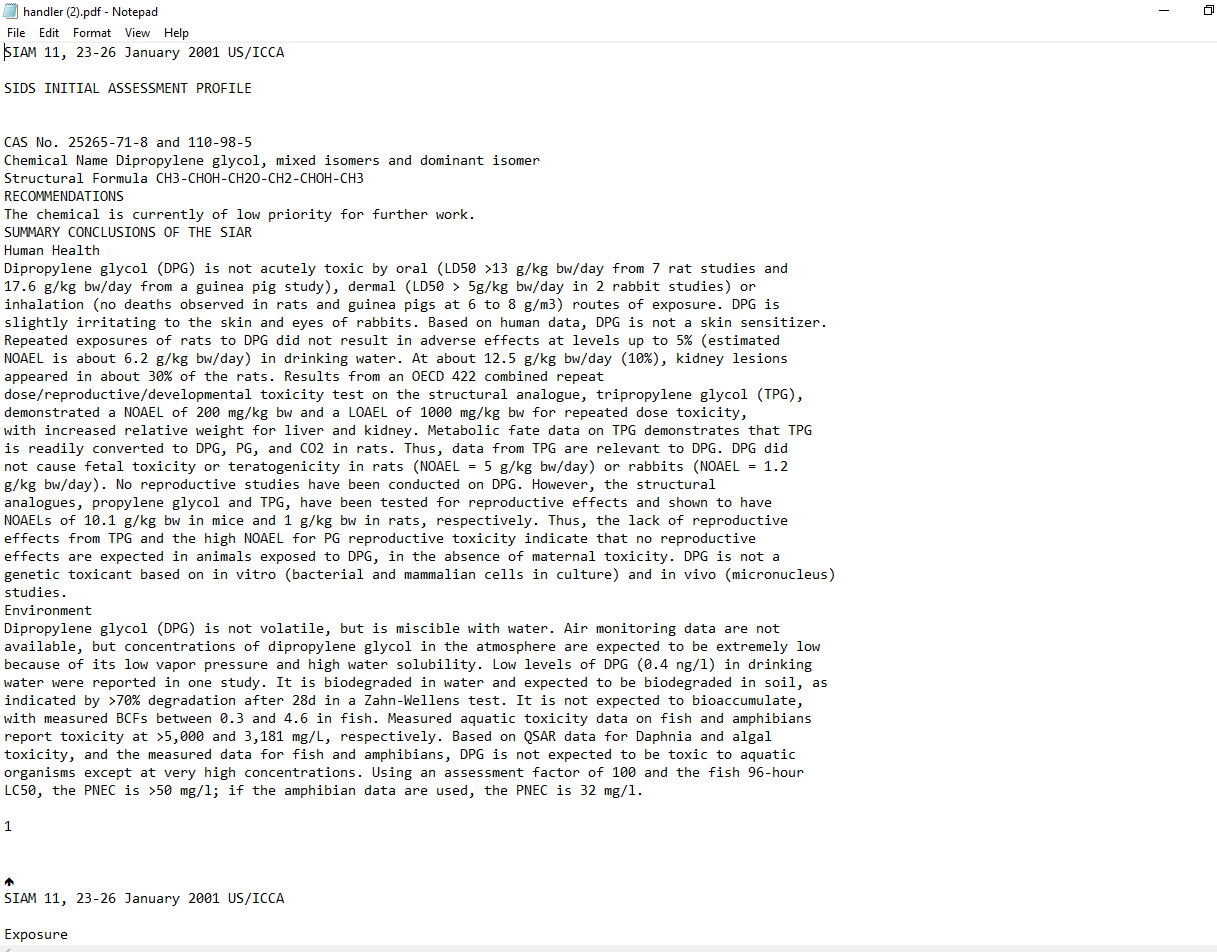
我认为这对这类PDF来说是一个失败的原因;然而,令人失望的是,我需要转换的许多PDF都是这种格式的。似乎被试图解决这一问题的问题所困扰。
无论如何,只是想知道是否可能禁用弹出消息,这可能会允许纯文本写入发生吗?
或者想不出别的什么。
回答 2
Stack Overflow用户
发布于 2022-09-05 08:50:37
来自:PDF格式的纯文本,不插入换行,但使用VBA保留回车。工作解决方案,但需要改进
更改: Encoding:=1252到65001不寻常的字符。
Sub LoopThroughFiles()
Dim StrFile As String
Dim pdfPath As String
StrFile = Dir("C:\temp\PDFs\")
fileRoot = "C:\temp\PDFs\"
If Right(fileRoot, 1) <> "\" Then fileRoot = fileRoot & "\" 'ensure terminating \
Do While Len(StrFile) > 0
Debug.Print StrFile
n = StrFile
pdfPath = fileRoot & StrFile
Debug.Print pdfPath
'Convert to WordDoc
success = ConvertPdf2(pdfPath, fileRoot & StrFile & ".doc")
StrFile = Dir
On Error Resume Next
oWd.Quit
'Convert to PlainText
Debug.Print pdfPath & ".doc"
success2 = GetTextFromWord(pdfPath & ".doc", n)
Loop
End Sub
'returns true if conversion was successful (based on whether `Open` succeeded or not)
Function ConvertPdf2(pdfPath As String, textPath As String) As Boolean
Dim AcroXApp As Acrobat.AcroApp
Dim AcroXAVDoc As Acrobat.AcroAVDoc
Dim AcroXPDDoc As Acrobat.AcroPDDoc
Dim jsObj As Object, success As Boolean
Set AcroXApp = CreateObject("AcroExch.App")
Set AcroXAVDoc = CreateObject("AcroExch.AVDoc")
success = AcroXAVDoc.Open(pdfPath, "Acrobat") '<<< returns false if fails
If success Then
Application.Wait (Now + TimeValue("0:00:2")) 'Helps PC have some time to go through data, can cause PC to freeze without
Set AcroXPDDoc = AcroXAVDoc.GetPDDoc
Set jsObj = AcroXPDDoc.GetJSObject
jsObj.SaveAs textPath, "com.adobe.acrobat.doc"
AcroXAVDoc.Close False
End If
AcroXApp.Hide
AcroXApp.Exit
ConvertPdf2 = success 'report success/failure
End Function
Function GetTextFromWord(DocStr As String, n)
Dim filePath As String
Dim fso As FileSystemObject
Dim fileStream As TextStream
Dim oWd As Object, oDoc As Object, fileRoot As String
Const wdFormatText As Long = 2, wdCRLF As Long = 0
Set fso = New FileSystemObject
Set oWd = CreateObject("word.application")
fileRoot = "C:\temp\PDFs" 'read this once
If Right(fileRoot, 1) <> "\" Then fileRoot = fileRoot & "\" 'ensure terminating \
Set oDoc = Nothing
On Error Resume Next 'ignore error if no document...
Set oDoc = oWd.Documents.Open(DocStr)
On Error GoTo 0 'stop ignoring errors
Debug.Print n
If Not oDoc Is Nothing Then
filePath = fileRoot & n & ".txt" 'filename
Debug.Print filePath
oDoc.SaveAs2 Filename:=filePath, _
FileFormat:=wdFormatText, LockComments:=False, Password:="", _
AddToRecentFiles:=True, WritePassword:="", ReadOnlyRecommended:=False, _
EmbedTrueTypeFonts:=False, SaveNativePictureFormat:=False, SaveFormsData _
:=False, SaveAsAOCELetter:=False, Encoding:=1252, InsertLineBreaks:=False _
, AllowSubstitutions:=True, LineEnding:=wdCRLF, CompatibilityMode:=0
oDoc.Close False
End If
oWd.Quit
GetTextFromWord = success2
End FunctionStack Overflow用户
发布于 2022-09-05 02:27:08
看起来你的Acrobat 11有问题,因为“为我工作”,但使用旧版本的Reader 9,然而它的文本端口作为纯文本,将成为从pdftotext获得的,例如左对齐单行,不确定10 Pro或20##是否足够好,什么时候Adobe按摩自然的pdf输出更丰富?
阅读器9导出为纯文本
在其他观众中打开足够好的功能,可以保存为word或wordpad。
或在保存为Docx或转换为文本之前编辑PDF
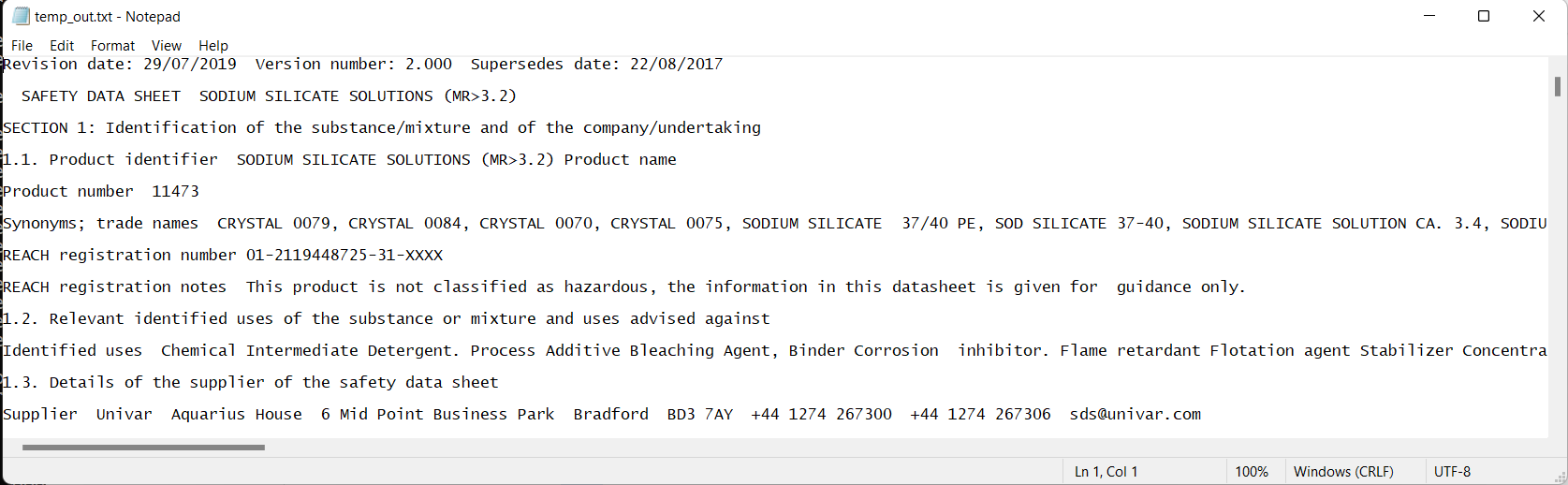
使用pdftotext将产生一个布局,反映页面上字符的真实输出(我称之为纯文本)。然而,您的愿望是删除单行提要(可能还有EOL连字符)。因此,这可以通过任何查找和替换文本处理后提取。在这里,我概述一种可能的方法。
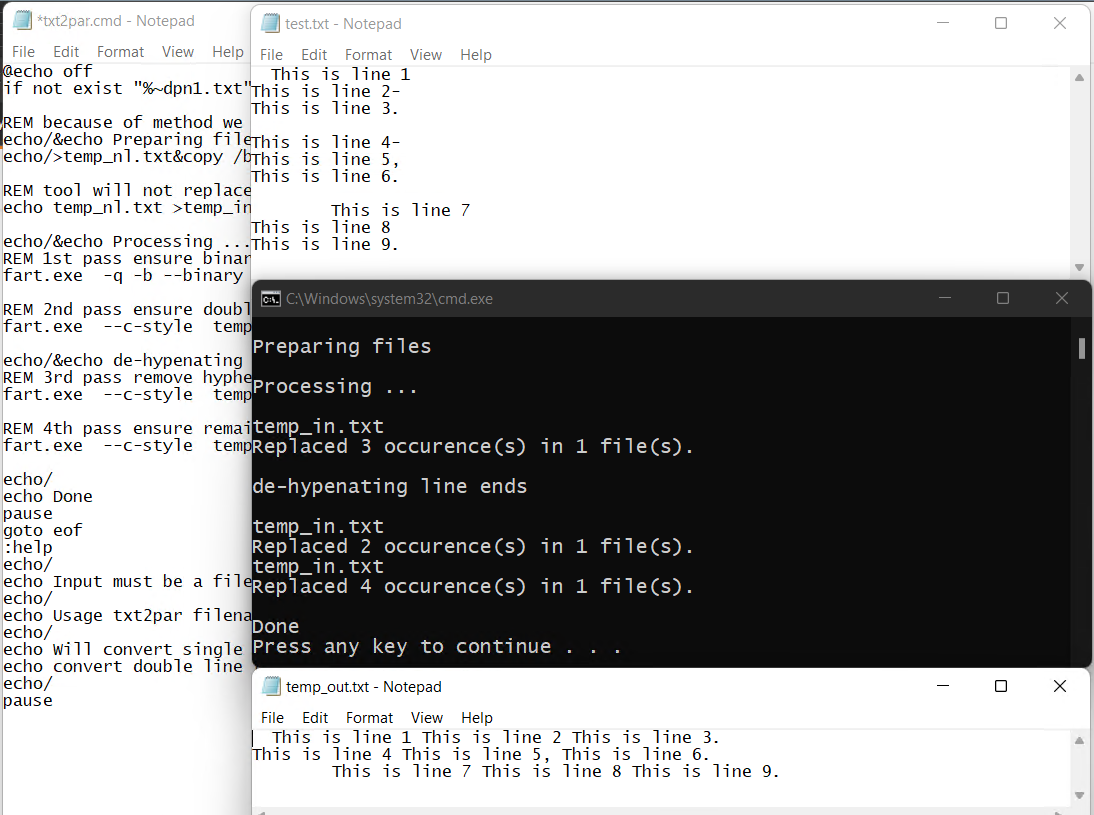
txt2par.cmd
@echo off
if not exist "%~dpn1.txt" goto help
REM because of method we need to append an extra new line to input (some cases may need two?)
echo/&echo Preparing files
echo/>temp_nl.txt© /b "%~dpn1.txt"+temp_nl.txt temp_out.txt >nul:
REM tool will not replace files in binary mode unless it sees there is a dummy backup to use !
echo temp_nl.txt >temp_out.txt.bak
echo/&echo Processing ...&echo/
REM 1st pass ensure binary line feeds are converted to some plain text
fart.exe -q -b --binary --c-style temp_out.txt "\x0D\x0A" "<NL>" >nul: 2>&1
REM 2nd pass ensure double "<NL><NL>" are converted back to single new line
fart.exe --c-style temp_out.txt "<NL><NL>" "\x0D\x0A\x0D\x0A"
echo/&echo de-hypenating line ends&echo/
REM 3rd pass remove hyphenation (Caution that may not always be desirable
fart.exe --c-style temp_out.txt "\x2D<NL>" "\x20"
REM 4th pass ensure remaining line markers are converted to single with little leading space
fart.exe --c-style temp_out.txt "\x20\x20\x20\x20\x20\x20\x20\x20" "\x20\x20\x20\x20"
REM 4th pass ensure remaining line markers are converted to single with little leading space
fart.exe --c-style temp_out.txt "\x20\x20\x20\x20" "\x20\x20"
REM 4th pass ensure remaining line markers are converted to single with little leading space
fart.exe --c-style temp_out.txt "\x20\x20\x20\x20" "\x20\x20"
REM 4th pass ensure remaining line markers are converted to single with little leading space
fart.exe --c-style temp_out.txt "\x20\x20\x20\x20" "\x20\x20"
REM 4th pass ensure remaining line markers are converted to single with little leading space
fart.exe --c-style temp_out.txt "\x20\x20\x20\x20" "\x20\x20"
REM 4th pass ensure remaining line markers are converted to single with little leading space
fart.exe --c-style temp_out.txt "\x20\x20\x20\x20" "\x20\x20"
REM 4th pass ensure remaining line markers are converted to single with little leading space
fart.exe --c-style temp_out.txt "\x20\x20\x20" "\x20\x20"
REM 4th pass ensure remaining line markers are converted to single with little leading space
fart.exe --c-style temp_out.txt "<NL>\x20\x20" "<NL>\x20"
REM 5th pass ensure remaining line markers are converted to single space
fart.exe --c-style temp_out.txt "<NL>" "\x20"
echo/
echo Done
pause
goto eof
:help
echo/
echo Input must be a filename.txt accepts drag and drop
echo/
echo Usage txt2par filename.txt
echo/
echo Will convert single line feeds to space and
echo convert double line feeds to single line gap
echo/
pause这可能是足够好的一些来源,但需要更多的考虑您的复杂模板布局。可能是通过不使用两个或更多空格的空格(在功能更强大的字符串编辑器中最简单,或者跳过未知循环)。
https://stackoverflow.com/questions/73567360
复制相似问题
腾讯云开发者
