
在执行pyspark数据报时出现错误
在执行pyspark数据报时出现错误
提问于 2022-09-08 01:51:41
当我试图读取hive表时,它会给GC开销限制超过错误。我已经试图改变spark.executor.memory和spark.driver.memory,但问题不断出现。
spark = SparkSession\
.builder\
.appName ("test")
.config("spark. executor.memory","20g"))\
.config("spark.network.timeout","200000s")\
.config("spark.master","yarn")\
.conFig("spark. submit.deployMode","client")\
.config("spark.driver.memory","25g")\
.config("spark. executor. instances","20")\
.config("spark. speculation","true")\
.config("spark.driver.maxResultsize","50g")\
.config("spark.sql.parquet.binaryAsstring","true")\
.config("spark.sql.broadcastrimeout","20000000ms")\
.config("spark.core.connection.ack.wait.timeout","6000s")\
.config("spark.driver.extraJavaOptions","-XX:MaxDirectMemorysize=999999998m-XX:+UseConcMarkSweepGC-XX:+CMSParallelRemarkEnabled XX:+UseCMSIniti")
.config("spark. executor.extraJavaOptions","-XX:MaxDirectMemorysize=999999998m -XX:+UseConcMarkSweepGC-XX:+CMSParallelRemarkEnabled-XX:+UseCMSIni")
.config ("spark.yarn.dist.files","/opt/mapr/hive/hive/conf/hive-site.xml")\
.config ("spark.sql.catalogImplementation","hive")\
.config ("spark.jars","/opt/pltf/cloak/lib/cloak-spark.jar,/app/spy/hive-contrib.jar")\
.config ("spark. yarn. archive","/opt/pltf/cloak/lib/spark-jars.zip")\
.config ("spark. shuffle.compress", "true")\
.config ("spark.shuffle.spill.compress", "true")\
.config ('spark. shuffle.io.maxRetries",1101) \
.config ("spark.sql.shuffle.partitions","1200" )\
.config ('spark.default.parallelism', '60000) \
.config ('spark.sql. shuffle.partitions' ,3000) \
. config ('spark.shuffle.registration.timeout', '10000 ) \
.config (spark. shuffle.registration.maxAttempts',5)\
.conFig ('spark.dynamicAllocation.minExecutors",'41)\
.config ('spark. yarn.queue', 'root-digviz')\
.config ('spark.memory. fraction','.7')\
.config ('spark.memory. storageFraction' ,'.5' )\
.enableHiveSupport()
getorCreate()
sc = spark.sparkContext
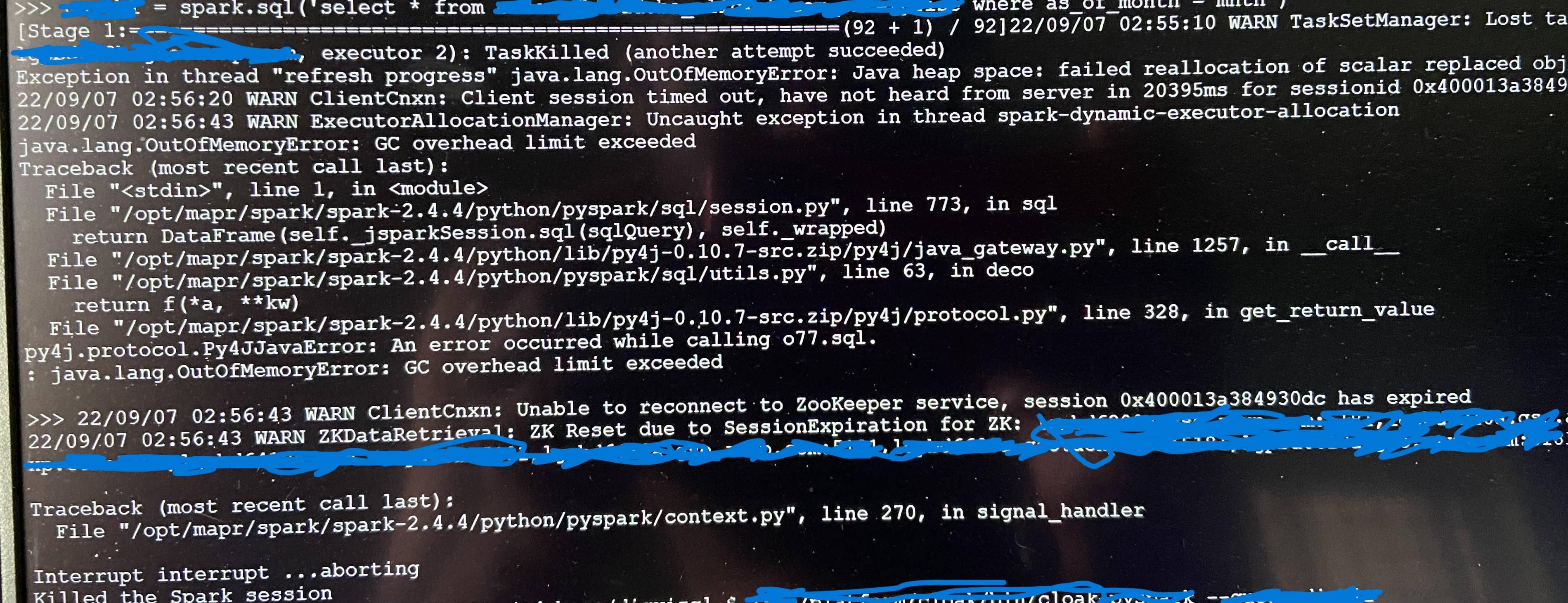
df = spark.sql("select * from db.emp_table where month=202206")请帮助设置正确的配置以解决GC问题。
错误快照
回答 1
Stack Overflow用户
发布于 2022-09-08 10:08:15
.config('spark.default.parallelism', 60000)你有60000颗核吗?
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73643004
复制相关文章
相似问题
腾讯云开发者
