
L2Fwd应用程序实现了很好的速率,当在同一端口上使用VFs时,当在不同端口上从VF发送流量到VF时,可以看到较低的速率。
发行摘要:
在双端口10 9Gbps网卡上,我的dpdk应用程序可以成功地维持每个端口上的~9 9Gbps流量(我在一个端口上接收流量,处理和发送通过同一个端口)。使用第二个应用程序在第二个端口上进行类似的处理)。
但是,如果我的应用程序在1端口上接收流量并将其发送到第2端口(内部),而另一个应用程序在第2端口接收通信量--我最多只能接收最多3.4Gbps的流量。除了这个速率,数据包被丢弃,但是DPDK统计信息中的输入计数没有增加。
详细发布:
我是在一个服务器上运行的,它有一个"X710 for 10GbE SFP+ 1572“以太网控制器,具有两个端口/物理功能。我在每个物理函数上创建了4个虚拟函数。
身体机能:
0000:08:00.0 'Ethernet Controller X710 for 10GbE SFP+ 1572' if=ens2f0 drv=i40e unused=vfio-pci *Active*
0000:08:00.1 'Ethernet Controller X710 for 10GbE SFP+ 1572' if=ens2f1 drv=i40e unused=vfio-pci *Active*机器规范:
CentOS 7.8.2003
Hardware:
Intel(R) Xeon(R) CPU L5520 @ 2.27GHz
L1d cache: 32K, L1i cache: 32K, L2 cache: 256K, L3 cache: 8192K
NIC: X710 for 10GbE SFP+ 1572
RAM: 70Gb
PCI:
Intel Corporation 5520/5500/X58 I/O Hub PCI Express
Capabilities: [90] Express (v2) Root Port (Slot-), MSI 00
LnkSta: Speed 5GT/s, Width x4,
isolcpu: 0,1,2,3,4,5,6,7,8,9,10
NUMA hardware:
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6 8 10 12 14
node 0 size: 36094 MB
node 1 cpus: 1 3 5 7 9 11 13 15
node 1 size: 36285 MB
Hugepage: size - 2MB and count - 1024模型-1(内部VF):运行两个DPDK l2fwd应用程序实例,即ApApp1和ApApp2。ApApp1is绑定2个VFs和2个核心,ApApp2绑定1个VF和1个核心。
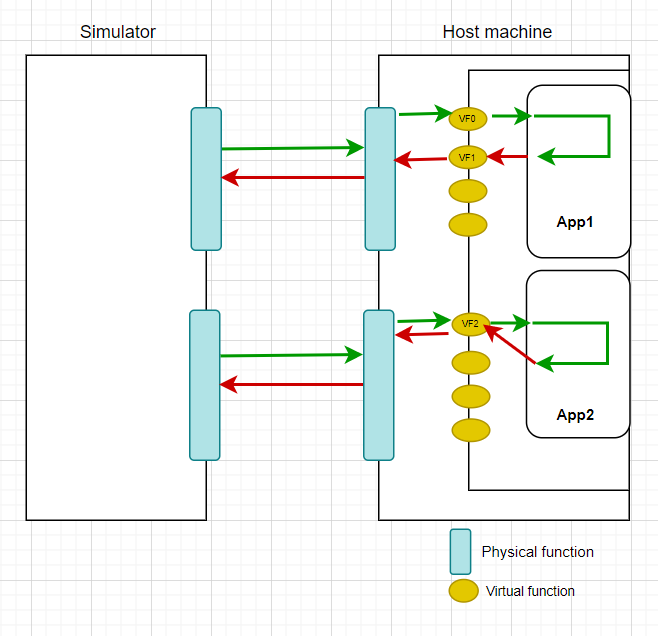
流量处理: App1在VF-0上接收外部通信量,并通过VF-1发送出去.App2在VF-2上接收外部通信量,并通过VF-2本身发送出去.
在该模型中,App1和App2共同接收8.8Gbps的数据,并在没有任何损失的情况下进行传输。
Model-2(inter ):I对l2fwd应用程序App1进行了修改,将外部流量发送给App2,App2接收并将其发送回App1,App1将流量发送到外部目的地。
{kind=link}
流量处理: App1在VF0上接收外部流量,并通过VF1将其发送到App2。App2在VF2上接收数据包,并通过VF2本身将其发送给App1。App1在VF1上接收来自App2的数据包,并通过VF0发送到外部目的地。
在该模型中,App1和App2加在一起只接收3.5Gbps,并且传输没有任何损失。
如果我试图提高通信速率,App1发送的数据包并不都是由App2接收的,反之亦然。请注意,在端口级统计数据中,imissed计数没有增加。(由此推断,丢包并不是由于足够的cpu周期,而是因为VFs之间的PCI通信)
但是,对于我来说,在VF内部通信的情况下,吞吐量没有问题。我有限的理解是,两个不同的物理功能之间的通信将通过PCI快速交换机进行。
性能会出现如此大的下降(两个10 Gbps端口的吞吐量低于4 Gbps),因此我需要更改设计吗?
可能是因为一些配置错误吗?请提出进一步的建议。
回答 1
Stack Overflow用户
发布于 2022-09-16 17:04:48
基于对该问题的分析,似乎存在一个与平台配置相关的问题,从而导致了这种影响。
问题:(吞吐量问题)无法实现基于maximum receive only upto 3.4Gbps的20 20Gbps双向(来自模拟器的入口和通过VF的应用出口)。
解决方案这很可能是以下原因
- 光纤、铜、DAC等互连电缆可能有故障。两个港口都不太可能。
- 这两个港口可能正在谈判半双工。不太可能,因为DPDK的默认设置强制全双工。
- 平台或主板没有设置正确的PCIe根或分配足够的车道。最有可能是
要识别PCIe车道问题,请使用sudo lscpi -vvvs [PCIe BDF] | gerp Lnk。将LnkCap与LnkSta进行比较。如果有错配,那么这是一个PCIe车道问题。
基于实时调试的编辑已经确定,确实存在PCIe链接问题。目前的Xeon平台只支持PCIe gen-2 4 x通道,而X710-T2卡需要PCie gen 3, 4x lanes。
在升级CPU和主板时推荐使用最少的Broadwell Xeon或更好的。
https://stackoverflow.com/questions/73663419
复制相似问题
腾讯云开发者
