Python大熊猫Dataframe比较
堆叠溢出的人,救命!
我对你们来说有个密码风格的问题。
想象一个场景,其中你有2个二维数组,更具体地说,2个数据处理与熊猫。
我需要比较这两个Dataframes和突出所有的差异,但有一个陷阱。这些数据帧中可能缺少行,这就使得这本身就更加困难,同时也会丢失单元格。我来举个例子。
import pandas as pd
x = [[0, 1, 2, 3],[4, 5, 6, 7],[8, 9, 10, 11],[12, 13, 14, 15]]
y = [[nan, 1, 2, 3],[4, 5, 6, nan],[12, 13, 14, 15]]
df1 = pd.DataFrame(x)
df2 = pd.DataFrame(y)如何识别所有丢失的单元格和丢失的行?
如果您可以创建代码来突出显示差异并将它们导出到excel工作表中,则可以获得额外的积分;)
回答 2
Stack Overflow用户
发布于 2022-09-09 21:32:22
阶段1
一个很好的起点是以下StackOverflow问题:https://stackoverflow.com/a/48647840/15965988
这将从两个表中删除100%重复的行。
阶段2
在此阶段,只存在有差异的行。从这里开始,我建议在每一行上循环。对于每一行,您都需要创建一些逻辑,以查询另一个dataframe,寻找类似的行。在该查询期间,请考虑只使用某些列进行查询。
祝你好运。
Stack Overflow用户
发布于 2022-09-10 00:52:48
示例数据集
稍微调整一下示例数据,让我们定义以下数据:
import pandas as pd
import numpy as np
x = [[0, 1, 2, 3],[4, 5, 6, 7],[8, 9, 10, 11],[12, 13, 14, 15]]
y = [[4, 5, 6, 99],[8, 9, np.nan, 11],[12, 13, 14, 15]]
df_ref = pd.DataFrame(x, index=range(4), columns=["a", "b","c","d"])
df = pd.DataFrame(y, index=[1,2,5], columns=["a", "b","c","d"])df_ref是您的“参考”数据。

和"df“的数据,您正在比较它。
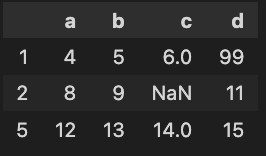
不同之处是:
- 行0和3缺少
- 新行(5)
- (0,"d")等于99,而不是3
- (2,"c")是NaN而不是10
F 213
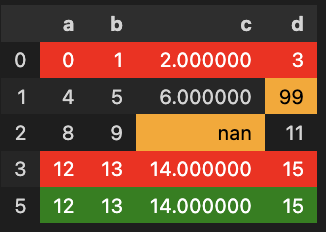
解决方案
以下解决方案突出说明:
红色的
- (未出现在df中的行索引)
- 中的“新行”(未出现在df_ref中的行索引)
- 中的橙色--公共行
的不同值
def get_dataframes_diff(df: pd.DataFrame, df_ref: pd.DataFrame, path_excel = None):
rows_new = df.index[~df.index.isin(df_ref.index)]
rows_del = df_ref.index[~df_ref.index.isin(df.index)]
rows_common = df_ref.index.intersection(df.index)
df_diff = pd.concat([df, df_ref.loc[rows_del]]).sort_index()
s = df_diff.style
def format_row(row, color: str = "white", bg_color: str = "green"):
return [f"color: {color}; background-color: {bg_color}"] * len(row)
s.apply(format_row, subset = (rows_new, df.columns), color="white", bg_color="green", axis=1)
s.apply(format_row, subset = (rows_del, df.columns), color="white", bg_color="red", axis=1)
mask = pd.DataFrame(True, index=df_diff.index, columns=df_diff.columns)
mask.loc[rows_same] = (df_ref.loc[rows_same] == df.loc[rows_same])
mask.replace(True, None, inplace=True)
mask.replace(False, "color: black; background-color: orange;", inplace=True)
s.apply(lambda _: mask, axis=None)
if path_excel is not None:
s.to_excel(path_excel)
return s 它规定:
get_dataframes_diff(df, df_ref)
解释
获取已删除行、新行和公共行的列表。
rows_new = df.index[~df.index.isin(df_ref.index)]
rows_del = df_ref.index[~df_ref.index.isin(df.index)]
rows_same = df_ref.index.intersection(df.index)通过将已删除的行添加到df数据框架中,创建"diff“数据
df_diff = pd.concat([df, df_ref.loc[rows_del]]).sort_index()使用Styler.apply以绿色突出显示新行,并将已删除的行改为红色(注意subset参数的使用):
def format_row(row, color: str = "white", bg_color: str = "green"):
return [f"color: {color}; background-color: {bg_color}"] * len(row)
df_diff.style.apply(format_row, subset = (rows_new, df.columns), color="white", bg_color="green", axis=1)
df_diff.style.apply(format_row, subset = (rows_del, df.columns), color="white", bg_color="red", axis=1)要突出显示公共行的值差异,请创建一个掩码数据,对于相同的元素等于True,在值不同时创建False
mask = pd.DataFrame(True, index=df_diff.index, columns=df_diff.columns)
mask.loc[rows_common] = (df_ref.loc[rows_common] == df.loc[rows_common])当真(相同的值),我们不应用任何样式。当假的时候,我们用橙色突出显示:
mask.replace(True, None, inplace=True)
mask.replace(False, "color: black; background-color: orange;", inplace=True)
df_diff.style.apply(lambda _: mask, axis=None)最后,如果要将其保存为excel文件,请提供指向path_excel参数的有效路径。
https://stackoverflow.com/questions/73667608
复制相似问题
腾讯云开发者
