
如何将图像OCR用于视频?
如何将图像OCR用于视频?
提问于 2022-09-13 05:08:26
目前我正在开发自动车牌识别系统。我已经使用yolov7的号码板检测和文本检测设施,从谷歌视觉API。我用测试图像测试了整个系统。现在我愿意开发一个系统来检测和读取视频源中的车牌。我可以为视频做检测部分,而我被卡住的地方是使用OCR作为视频中检测到的绑定框。
对于图像,我首先应用经过训练的YOLOv7模型,提取出车牌,并将检测到的车牌保存为从目录中的原始图像中裁剪出来的部分。然后将OCR应用于该裁剪部件(号码板),并读取文本。
测试样本:

NP检测:

检测到的NP:(OCR应用于这幅裁剪的图像)

检测到的文本:
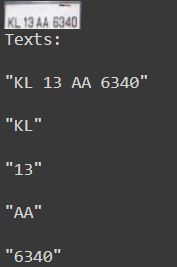
我可以从视频中检测到车牌号码,但无法找到一种方法来冻结检测到号码板的帧,并应用ocr或任何其他方式读取号码盘。
有办法做到这一点吗?任何帮助都将不胜感激。
回答 1
Stack Overflow用户
发布于 2022-09-13 05:40:23
尝试从出现边界框的每个帧中获取边界框的坐标,并应用OCR。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73697754
复制相关文章
相似问题
腾讯云开发者
