
如何使用多索引将另一个子列添加到dataframe中
如何使用多索引将另一个子列添加到dataframe中
提问于 2022-09-13 08:24:21
我正在尝试添加第三列“生产力”,以便像Admin这样的每个角色都有三个子列-- produktiv、unproduktiv和Productivity。
生产率计算如下:
生产力= Produktiv / (Produktiv + Unproduktiv) * 100
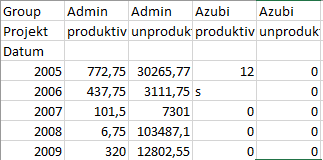
(别介意,我不得不匿名)
这是df.columns的输出
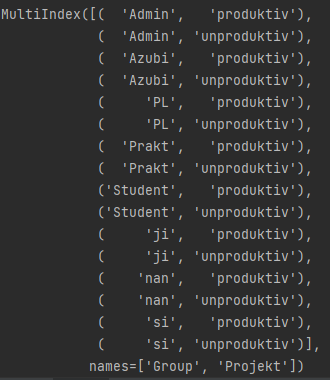
任何帮助都将不胜感激。谢谢。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-09-13 08:32:46
如果只有Produktiv和Unproduktiv级别的sum可能被MultiIndex的第一级聚合,那么用Produktiv除以rename,再用concat附加到原始数据格式的rename第二级
df1 = (df.xs('Produktiv', axis=1, level=1, drop_level=False)
.div(df.groupby(level=0, axis=1).sum(), level=0).mul(100))
df = (pd.concat([df, df1.rename(columns={'Produktiv':'Productivity'}, level=1)], axis=1)
.sort_index(axis=1)
.reindex(['Produktiv','Unproduktiv','Productivity'], level=1, axis=1))
print (df)另一个想法是先通过Produktiv, Unproduktiv获得两个切片,然后通过pd.concat添加级:
df1 = df.xs('Produktiv', axis=1, level=1)
df2 = df.xs('Unproduktiv', axis=1, level=1)
df11 = (pd.concat({'Productivity':df1.div(df1.add(df2)).mul(100)}, axis=1)
.swaplevel(0,1,axis=1))
df = (pd.concat([df, df11], axis=1)
.sort_index(axis=1)
.reindex(['Produktiv','Unproduktiv','Productivity'], level=1, axis=1))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73699769
复制相关文章
相似问题
腾讯云开发者
