
如何检测大数据集中的多元异常值?
如何检测大数据集中的多元异常值?
提问于 2022-09-21 14:59:18
如何在50多个变量的大数据中检测多变量离群值。我是否需要绘制所有变量,还是必须对它们进行分组,以独立和因变量为基础,还是需要一种算法来解决这个问题?
回答 1
Stack Overflow用户
发布于 2022-09-21 18:54:39
我们确实有一种特殊类型的距离公式,我们用它来寻找多元离群值。它被称为Mahalanobis距离。
MD是一种度量,它通过推广z-分数来确定分布D和数据点x之间的分离,MD从标准差的角度表示x离D平均值有多远。
您可以使用下面的函数来查找异常值。它返回异常值的索引。
from scipy.stats import chi2
import scipy as sp
import numpy as np
def mahalanobis_method(df):
#M-Distance
x_minus_mean = df - np.mean(df)
cov = np.cov(df.values.T) #Covariance
inv_covmat = sp.linalg.inv(cov) #Inverse covariance
left_term = np.dot(x_minus_mean, inv_covmat)
mahal = np.dot(left_term, x_minus_mean.T)
md = np.sqrt(mahal.diagonal())
#Flag as outliers
outliers = []
#Cut-off point
C = np.sqrt(chi2.ppf((1-0.001), df=df.shape[1])) #degrees of freedom = number of variables
for i, v in enumerate(md):
if v > C:
outliers.append(i)
else:
continue
return outliers, md如果您想研究更多关于Mahalanobis距离及其公式的内容,您可以阅读这个博客。
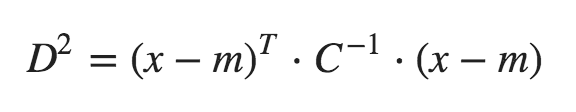
那么,如何理解上述公式呢?让我们取(x - m)^T。C^(-1)项(x - m)本质上是向量与平均值的距离。然后,我们将其除以协方差矩阵(或乘以协方差矩阵的逆)。如果您仔细想想,这实际上是一个与常规标准化(z = (x - mu)/sigma)相当的多元变量。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73802995
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号