
Regex \P{IsHan}在Java8中不能很好地工作
Regex \P{IsHan}在Java8中不能很好地工作
提问于 2022-09-27 04:52:01
我要删除字符串中的所有非中文字符,并保留汉字.
下面是一个示例:
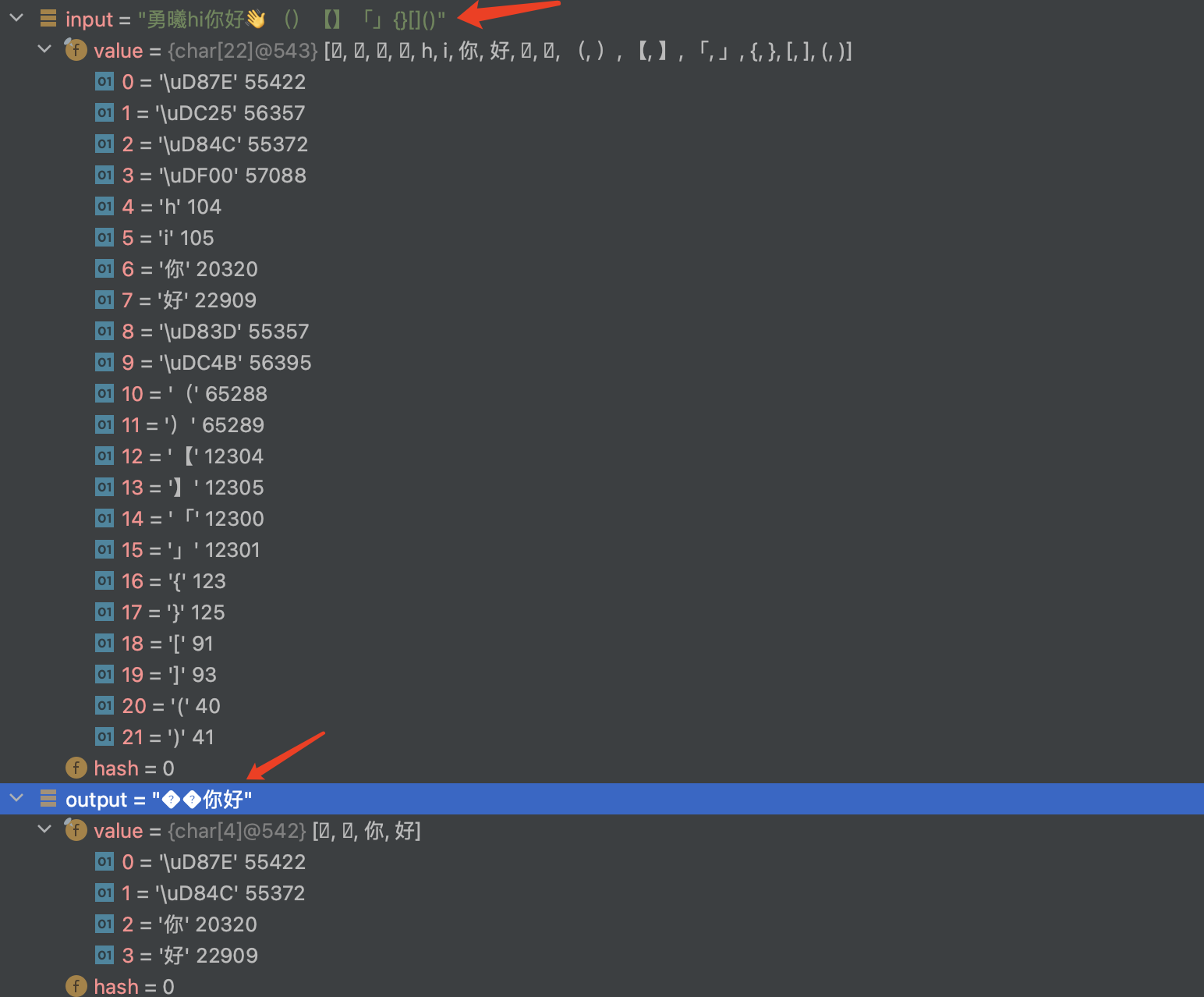
输入-> hi你好()【】「」{}[]()
输出-> 你好
首先,我尝试提取所有汉字,并使用以下代码将每个汉字附加到StringBuilder中:
public static String extractAllChineseCharacters(String input){
Matcher matcher = Pattern.compile("\\p{IsHan}").matcher(input);
StringBuilder output = new StringBuilder();
while(matcher.find()){
output.append(input.substring(matcher.start(),matcher.end()));
}
return output.toString();
}代码运行良好,但我想要一个更简洁的代码。
然后,我尝试使用以下代码将所有非汉字替换为"“
public static String replaceCharacters(String input){
Matcher matcher = Pattern.compile("\\P{IsHan}").matcher(input);
return matcher.replaceAll("");
}但代码不像我预期的那样起作用。
当输入为hi你好()【】「」{}[]()时,
输出为??你好
我进入调试模式,并找到输出的charSequences is \uD87E\uD84e你好
我知道java采用UTF-16将代码单元存储在char变量中,因此(U+2F825)在charSequence中以代理项对\uD87E\uDC25的形式出现,而(U+23300)则以\uD84C\uDF00的形式出现。
我的问题是: regex模式"\P{IsHan}“可以将\uD87E\uDC25 25两个字符匹配为"",但是regex模式”\P{IsHan}“不能精确匹配非中文character.Why,是吗?
有人能帮忙吗?提前感谢!
回答 1
Stack Overflow用户
发布于 2022-09-27 07:32:44
\p{IsHan}的使用在Java8中有效-参见下面。也许输入编码是使匹配失败的一种方式?
关于“代码运行良好,但我需要一个更简洁的代码”,而不是匹配您想要的,匹配您不想要的,然后删除它:
public static String extractAllChineseCharacters(String input) {
return input.replaceAll("\\P{IsHan}", "");
}FYI:
\p{IsHan}"与任何汉字匹配\P{IsHan}"匹配任何非汉字字符。
测试:
String input = "\uD87E\uDC25\uD84C\uDF00hi你好\uD83D\uDC4B()【】「」{}[]()";
System.out.println(input);
System.out.println(input.replaceAll("\\P{IsHan}", ""));输出:
hi你好()【】「」{}[]()
你好页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73862541
复制相关文章
相似问题
腾讯云开发者
