
如何从SEC Edgar python和json获取数据
如何从SEC Edgar python和json获取数据
提问于 2022-09-27 05:47:13
在下面的页面中,有一个json链接作为数据源:https://www.sec.gov/edgar/browse/?CIK=1067983&owner=exclude数据源: CIK0001067983.json -> https://data.sec.gov/submissions/CIK0001067983.json
这是我的代码(工作正常!):
headers = {
"Host": "www.sec.gov",
"User-Agent": "jo boulement jo@gmx.at",
"Accept-Encoding": "gzip, deflate"
}
sec_url = "https://data.sec.gov/submissions/CIK0001067983.json"
resp = requests.get(sec_url, headers=headers)
with open("e:\\sec_api_of_1448574_7.html", "w", encoding="utf-8") as my_file:
my_file.write(resp.text)但结果是,我得到了一个文件,如下所示:在这里输入图像描述
{kind=link}
错误404:页面未找到Oops!找不到页面。
这里出了什么问题?json-link:https://data.sec.gov/submissions/CIK0001067983.json很好,因为手工从页面下载很好。希望有人能给我个提示!谢谢!
回答 3
Stack Overflow用户
发布于 2022-09-27 07:19:41
谢谢你的帮助..。我有解决办法..。
sec.gov的文档说明如下:
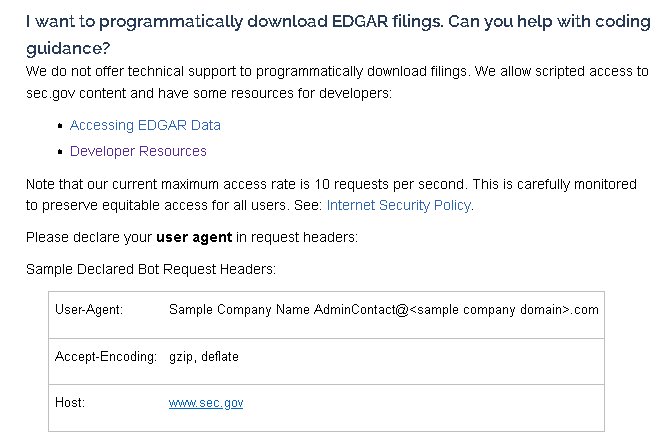
https://www.sec.gov/os/webmaster-faq#user-agent
但是标题"HOST“导致"404页未找到”.
但是这个标题工作得很好:
headers = {
"User-Agent": "jo boulement jo@gmx.at",
"Accept-Encoding": "gzip, deflate"
}疯了!因为文档中说的是别的东西:
Stack Overflow用户
发布于 2022-09-27 06:10:41
web服务器检查在请求中发送的标头,如果不包括某些标头,则可能决定返回错误页。在这种情况下,如果您不包括有效的用户代理,它们就会返回一个错误。
这对我来说很管用:
import requests
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'}
url = "https://data.sec.gov/submissions/CIK0001067983.json"
payload={}
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73862886
复制相关文章
相似问题
腾讯云开发者
