
根据一个数据帧中的值是否在第二个数据帧的范围内创建新列
根据一个数据帧中的值是否在第二个数据帧的范围内创建新列
提问于 2022-09-27 13:40:22
我有一个输出数据框架,其中包含对目标声音在一组录音中的位置的预测。数据帧具有sound.file名称、开始时间和结束时间。下面是我的数据的一个示例:
preds = pd.DataFrame({
'sound.file':np.random.choice( ['A','B','C'], 20),
'start':np.random.choice(10, 20),
})
preds['end'] = preds['start'] + np.random.choice([1,2], 20)然后,我有一个参考数据框架,其中包含sound.files名称和目标信号的实际开始和结束时间。引用检测不会是整数,因为它们是记录内呼叫的真正时间。
ref = pd.DataFrame({
'sound.file':np.random.choice( ['A','B','C'], 5),
'start':np.random.uniform(10, 5),
})
ref['end'] = ref['start'] + np.random.uniform([1,2], 5)我想在preds数据帧中添加一列,如果预测的信号与来自同一sound.file的实际信号重叠,则该列具有1;如果没有,则添加0。
我的输出应该如下所示:
preds['match'] = np.random.choice([0,1], 20)
preds我可以这样做,这是R,有几种不同的方法来做,例如,this。但是,我不熟悉python,因此需要一些帮助。
Stack Overflow用户
回答已采纳
发布于 2022-10-03 15:43:04
回答你的职位
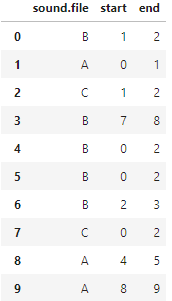
使用运行您的代码的以下随机数据文件:preds
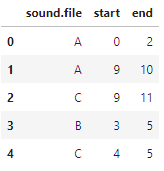
ref
有一种方法可以做到:
# Add interval as a column (e.g. start=1 and end=4 => actual={1, 2, 3, 4}) and groupby
ref["actual"] = ref.apply(lambda x: set(range(x["start"], x["end"] + 1)), axis=1)
ref = ref.groupby("sound.file").agg({"actual": list}).reset_index()
# Add interval as a column
preds["predicted"] = preds.apply(lambda x: set(range(x["start"], x["end"] + 1)), axis=1)
# Add actual column to preds
preds = pd.merge(left=preds, right=ref, on="sound.file", how="left")
# Deal with NaN values
preds["actual"] = preds["actual"].apply(lambda x: [{}] if x is np.nan else x)
# Check for overlaps
preds["match"] = preds.apply(
lambda x: 1
if any([x["predicted"].intersection(actual) for actual in x["actual"]])
else 0,
axis=1,
)
# Cleanup
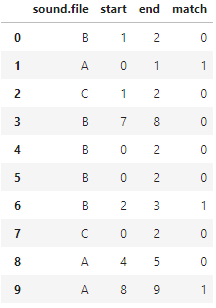
preds = preds.drop(columns=["predicted", "actual"])所以preds
超出你的职位范围
下面是如何处理连续的间隔(浮点值)。
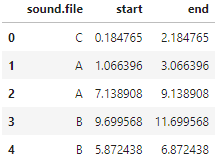
# Setup
preds = pd.DataFrame(
{
"sound.file": np.random.choice(["A", "B", "C"], 20),
"start": np.random.uniform(low=0, high=10, size=20),
}
)
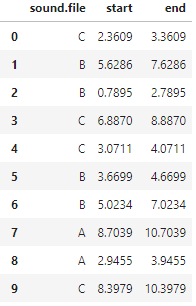
preds["end"] = preds["start"] + np.random.choice([1, 2], 20)preds
ref = pd.DataFrame(
{
"sound.file": np.random.choice(["A", "B", "C"], 5),
"start": np.random.uniform(low=0, high=10, size=5),
}
)
ref["end"] = ref["start"] + np.random.choice([1, 2], 5)ref
# Add interval as a column (e.g. start=1.2358 and end=4.4987 => actual=[1.2358, 4.4987]
# and groupby
ref["actual"] = ref[["start", "end"]].apply(lambda x: round(x, 4)).values.tolist()
ref = ref.groupby("sound.file").agg({"actual": sorted}).reset_index()
# Add actual column to preds
preds = pd.merge(left=preds, right=ref, on="sound.file", how="left")
# Deal with NaN values
preds["actual"] = preds["actual"].apply(lambda x: [[-1]] if x is np.nan else x)
# Check for overlaps
preds["match"] = preds.apply(
lambda x: 1
if any(
[(x["start"] >= period[0]) & (x["end"] <= period[-1]) for period in x["actual"]]
)
| any(
[
(x["start"] >= period[0]) & (x["start"] <= period[-1])
for period in x["actual"]
]
)
| any(
[(x["end"] >= period[0]) & (x["end"] <= period[-1]) for period in x["actual"]]
)
| any(
[(x["start"] <= period[0]) & (x["end"] >= period[-1]) for period in x["actual"]]
)
else 0,
axis=1,
)
# Cleanup
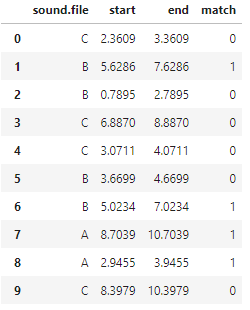
preds = preds.drop(columns="actual")所以preds
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73868620
复制相关文章
相似问题
腾讯云开发者
