
根据唯一的列值迭代颜色列表,使用来自第二列的值来区别深色和浅色-朱庇特笔记本
根据唯一的列值迭代颜色列表,使用来自第二列的值来区别深色和浅色-朱庇特笔记本
提问于 2022-09-28 21:26:05
我用的是木星笔记本。我将两个DataFrames组合在一起,因此为了区分这两个,我创建了一个新的第三列“颜色代码”,其中有两个值'a‘和'b’。我没有问题,迭代的颜色列表,我已经定义,但我需要能够着色黑暗和光取决于独特的列和‘颜色代码’列。
我下面有个MRE。对于大示例DataFrame表示歉意,只需要能够展示我正在努力实现的目标。
df1 = pd.DataFrame({'x1':['a', 'a', 'a', 'a', 'a', 'a', 'b', 'b', 'b', 'b', 'b', 'b', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'c', 'd', 'd', 'd', 'd'],
'x2':['3','4','8','0','11','1','15','5','67','3','1','4','5','88','9','3','7','2','3','43','34','56','96','26'],
'Color Mode':['a','a','b','b','b','b','a','a','a','a','b','b','a','b','b','b','b','b','b','b','a','a','a','b']})def Color_Unique(s):
df = s.copy()
color_map1 = {}
color_map2 = {}
x = pd.DataFrame({'Color Mode': ['a']})
y = pd.DataFrame({'Color Mode': ['b']})
Trade_Cusip_Combo_Key = df['x1'].unique()
if x.any(axis=None):
colors_to_use = ['background-color: #ADD8E6', 'background-color: #90ee90', 'background-color: #FFD580', 'background-color: #CBC3E3', 'background-color: #D3D3D3', 'background-color: #C4A484']
colors_cycle = cycle(colors_to_use)
for Trade_Cusip_Combo in Trade_Cusip_Combo_Key:
color_map1[Trade_Cusip_Combo] = next(colors_cycle)
for index, row in df.iterrows():
if row['x1'] in Trade_Cusip_Combo_Key:
Trade_Cusip_Combo = row['x1']
my_color = color_map1[Trade_Cusip_Combo]
df.loc[index,:] = my_color
else:
df.loc[index,:] = 'background-color: '
return df
elif y.any(axis=None):
colors_to_use = ['background-color: #ADD8E6', 'background-color: #90ee90', 'background-color: #FFD580', 'background-color: #CBC3E3', 'background-color: #D3D3D3', 'background-color: #C4A484']
colors_cycle = cycle(colors_to_use)
for Trade_Cusip_Combo in Trade_Cusip_Combo_Key:
color_map2[Trade_Cusip_Combo] = next(colors_cycle)
for index, row in df.iterrows():
if row['x1'] in Trade_Cusip_Combo_Key:
Trade_Cusip_Combo = row['x1']
my_color = color_map2[Trade_Cusip_Combo]
df.loc[index,:] = my_color
else:
df.loc[index,:] = 'background-color: '
return df
else:
print("boken")df4 = df1.style.apply(Color_Unique, axis=None)df4{kind=link}
{kind=link}
当列'x1‘值相同时,您会注意到暗色与浅色交替,但是列’色彩模式‘值要么是'a’(暗颜色),要么'b‘(较浅颜色)。我需要我的函数能够迭代我定义的基于列'x1‘和列’颜色模式‘的深色和浅色颜色,并且在每个组被着色后跳过一行(从蓝色到绿色到橙色到紫色)。
new_df1 = pd.DataFrame({'x1':['axe', 'axe', 'axe', 'axe', 'axe', 'axe', 'bench', 'bench', 'bench',
'bench', 'bench', 'bench', 'crunch', 'crunch', 'crunch', 'crunch', 'crunch', 'crunch',
'crunch', 'crunch', 'deed', 'deed', 'deed', 'deed'],
'x2':['Bob','Bob','Bob','Bob','Bob','Bob','Leo','Leo','Leo','Leo',
'Leo','Leo','Jamie','Jamie','Jamie','Jamie','Jamie','Jamie','Jamie','Jamie',
'John','John','John','Luke'],
'Price':['3.00','3.00','3.00','3.00','3.00','3.00','15.00','80.00','15.00','15.00',
'15.00','15.00','4.00','4.00','4.00','68.00','4.00','4.00','39.00','4.00',
'5.00','5.00','5.00','27.00'],
'Color Mode':['a','a','b','b','b','b','a','a','a',
'a','b','b','a','b','b','b','b','b',
'b','b','a','a','a','b']})新图片:新图景
{kind=link}
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-09-29 00:10:14
在转向练习的“样式”部分之前,让我们使用一个函数将空白行插入到df中。我们可以这样做:
import pandas as pd
df1 = pd.DataFrame({'x1':['a', 'a', 'a', 'a', 'a', 'a', 'b', 'b', 'b',
'b', 'b', 'b', 'c', 'c', 'c', 'c', 'c', 'c',
'c', 'c', 'd', 'd', 'd', 'd'],
'x2':['3','4','8','0','11','1','15','5','67','3',
'1','4','5','88','9','3','7','2','3','43',
'34','56','96','26'],
'Color Mode':['a','a','b','b','b','b','a','a','a',
'a','b','b','a','b','b','b','b','b',
'b','b','a','a','a','b']})
def blank_rows(df, col_name):
insert_idx = [v[-1]+1 for v in df.groupby(col_name).groups.values()]
for i, idx in enumerate(insert_idx[:-1]):
temp = pd.DataFrame({k: '' for k in df.columns}, index=[idx+i])
df = pd.concat([df.iloc[:idx+i], temp, df.iloc[idx+i:]])\
.reset_index(drop=True)
return df
# add `col_name` (e.g. `x1`) to specify which groups need to be split up
df = blank_rows(df1, 'x1')
# N.B. the groups inside column `col_name` need to be sorted,
# and the index needs to be "regular" (i.e. `0,1,2...`).
# E.g. `df = blank_rows(df1, 'Color Mode')` would get you a nonsensical result;
# Instead you would want to use:
# `df = blank_rows(df1.sort_values('Color Mode').reset_index(drop=True),
# 'Color Mode')`df现在将包含空行,如下所示:
df.iloc[[5,6,7,12,13,14],:]
现在,让我们应用一个函数来处理样式。例如:
from itertools import cycle
def color_unique(df_input):
df = df_input.copy()
colors = ['#8EA9DB', '#D9E1F2', # blues
'#A9D08E', '#E2EFDA', # greens
'#F4B084', '#FCE4D6', # reds
'#9751CB', '#DEC8EE'] # purples
colors_cycle = cycle(colors)
groups = df.groupby(['x1','Color Mode']).groups
for k, v in groups.items():
if '' in k:
df.iloc[v] = f'background-color: white;'
else:
df.iloc[v] = f'background-color: {next(colors_cycle)};'
return df
df_styled = df.style.apply(color_unique, axis=None)
df_styled结果:
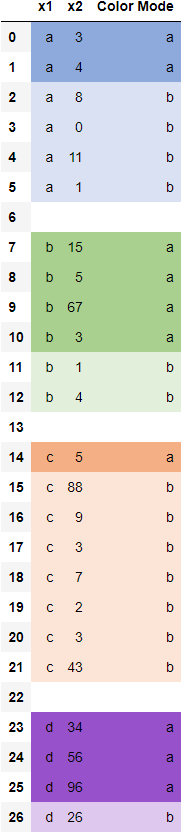
解释
- 创建一个具有深色/浅色对的列表。由于我们使用的是来自
cycle的itertools,所以列表不需要详尽无遗。(N.B.:上面的函数期望x1中的每个组总是在基于Color Mode的两个子组中分裂。例如,如果您期望组只具有a,而不是b,则需要调整上面的函数!) - 使用
df.groupby隔离不同的组。确保添加sort=False以保留组的原始顺序。 Groupby.groups属性存储以“组名”(例如('a', 'a'))作为键的dict,并将相关的索引值存储为值(例如,对于('a', 'a'),值为Int64Index([0, 1], dtype='int64'))。- 我们希望使用每个组的值来使用
.iloc连续地从df中选择切片并分配颜色。但是,我们希望跳过具有键(''),('')的组,为此,我们希望在group.items()上迭代并同时捕获(k)ey和(v)alue。如果键(元组)包含空字符串,则将行“白色”涂上颜色,否则将从颜色列表中指定下一种颜色。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73887953
复制相关文章
相似问题
腾讯云开发者
