
在这种情况下,我如何生成每个用户的弹道段呢?
在这种情况下,我如何生成每个用户的弹道段呢?
提问于 2022-10-04 09:34:58
我有一个包含用户轨迹和段的数据。一段轨迹被认为是两站之间轨迹的一部分.所以我的df是这样的:
df = pd.DataFrame(
{
'trajectory': [1,1,1,2,2,2,3,3,3,4],
'segment': [0,2,4,1,3,5,2,5,1,2],
'user': ['A','A','A','B','B','B','A','A','A','C']
}
)
df
trajectory segment user
0 1 0 A
1 1 2 A
2 1 4 A
3 2 1 B
4 2 3 B
5 2 5 B
6 3 2 A
7 3 5 A
8 3 1 A
9 4 2 C- 用户轨迹中的分段数不是顺序的,例如用户
A的trajectory 3是:2,5,so 2段。 - --一些用户贡献的片段比其他的多。
我想要绘制每个用户的每个轨迹的段数的CDF。这是为了了解平均而言,一个用户每个轨迹贡献了多少段?
回答 1
Stack Overflow用户
发布于 2022-10-04 16:35:40
让我先扩展一下你的数据,这样就可以说明:
import pandas as pd
import seaborn as sns
# 10x sample from your initial data
trajectory = pd.Series([1,1,1,2,2,2,3,3,3,4]).sample(frac=10, replace=True)
segment = pd.Series([0,2,4,1,3,5,2,5,1,2]).sample(frac=10, replace=True)
user = pd.Series(['A','A','A','B','B','B','A','A','A','C']).sample(frac=10, replace=True)
# rebuild the DataFrame with upsampled data
df = pd.DataFrame({'trajectory': trajectory.to_numpy(),
'segment': segment.to_numpy(),
'user': user.to_numpy()})现在让我们将df按trajectory和user分组,使用count在每个轨迹中查找每个用户的段数:
# reset index so 'trajectory' and 'user' become columns again
df_grouped = df.groupby(['trajectory', 'user'])['segment'].agg('count').reset_index()
#rename the columns to add a name for aggregation column
df_grouped.columns = ['trajectory', 'user', 'segment_count']然后用海运的df_grouped绘制.kdeplot(),使用cumulative=True绘制CDF:
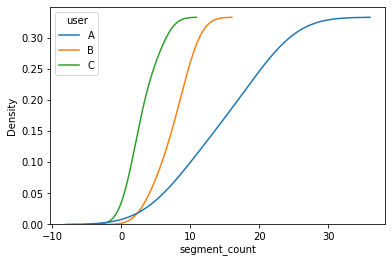
sns.kdeplot(data=df_grouped, x='segment_count', hue='user', cumulative=True)输出:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73945896
复制相关文章
相似问题
腾讯云开发者
