
Pyspark : RDD缓存总是序列化数据。
Pyspark : RDD缓存总是序列化数据。
提问于 2022-10-05 15:46:27
我浏览了多个文档,表示执行缓存/在星星之火上持久化的默认行为将RDD存储为反序列化对象到JVM内存。
但是,当我使用示例文件(5-6行)运行一些测试时,火花用户界面中部分下的存储级别总是显示为内存序列化的1x复制。
如果我错过了什么,谁能帮我弄明白吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-10-07 06:00:20
我做了和你一样的测试,我准备了一个小文件:
id;name;value
1,test,full
2,test,empty
3,test,important
4,test2,sadfdsf
5,test4,gfdsfgdfg然后,我用Spark3.2.1和Scala2.12启动了10.4 databricks社区集群,并执行了以下代码:
//small files
val rddWhole = spark.sparkContext.textFile("dbfs:/FileStore/shared_uploads/my-email@gmail.com/very_small_csv.csv")
rddWhole.cache().count()作为SparkUI的结果,我可以看到以下内容:

同样适用于更大的文件(屏幕截图从3.3,但它相同)

你的env上也是一样的吗?
编辑:我可以确认这一点,正如Python序列化的注释中所说的那样。
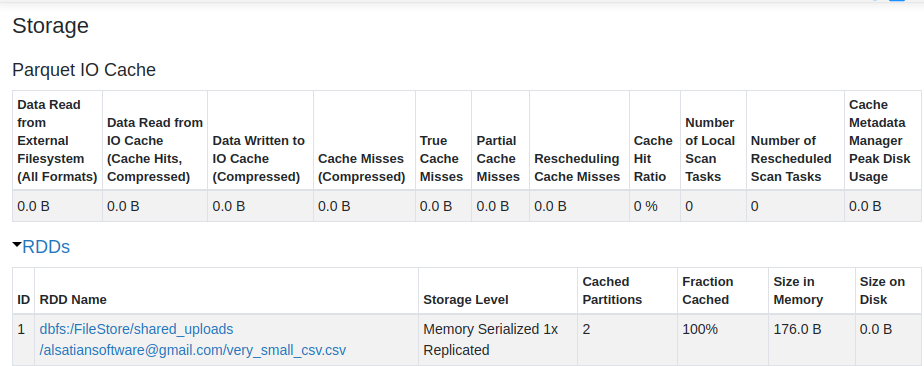
我检查了源代码,我可以看到Scala和Python之间的区别。对于rdd,它们都使用MEMORY_ONLY级别进行缓存,但它是用Python以外的其他方式定义的。
val MEMORY_ONLY = new StorageLevel(false, true, false, true) //Scala
StorageLevel.MEMORY_ONLY = StorageLevel(False, True, False, False) //Python在最后一个参数被反序列化的地方,所以如果认为这是不同的原因,但是现在我不知道原因是什么。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73963002
复制相关文章
相似问题
腾讯云开发者
